如果编写
SQL查询时没有分析它们必须实现
的算法 ,那么在性能方面通常不会带来任何好处。
这样的请求
喜欢“消耗”处理器时间并几乎从头开始
主动读取数据 。 而且,这不一定是某种复杂的查询,相反-编写的越简单,出现问题的机会就越大。 如果JOIN运算符起作用了...
就其本身而言,联接表既无害也无用-它只是一种工具,但是您必须能够使用它。
监督分组
首先,举一个非常简单的例子。
有100个条目的“词典”(例如,这些是俄罗斯联邦的地区):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
...,并附有每10万个条目的相关“事实”表:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
现在,让我们尝试计算每个“区域”的值之和。
如所听到的,它是书面的
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
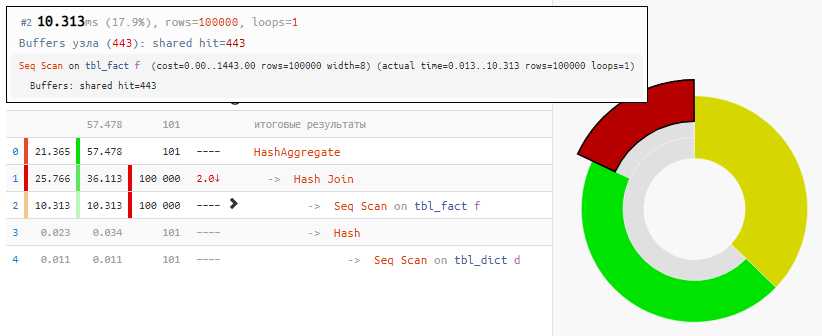
读取数据本身仅花费了18%的时间,其余时间正在处理:
 [看explain.tensor.ru]
[看explain.tensor.ru]所有这些都是因为Hash Join和Hash Aggregate必须处理10万条记录,这是因为我们希望
按链接表的字段进行
分组 。
我们运用创造力
但是此字段的值等于聚合表中该字段的值! 也就是说,没有人打扰我们
首先将“事实”归类
,然后才建立联系 :
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
 [看explain.tensor.ru]
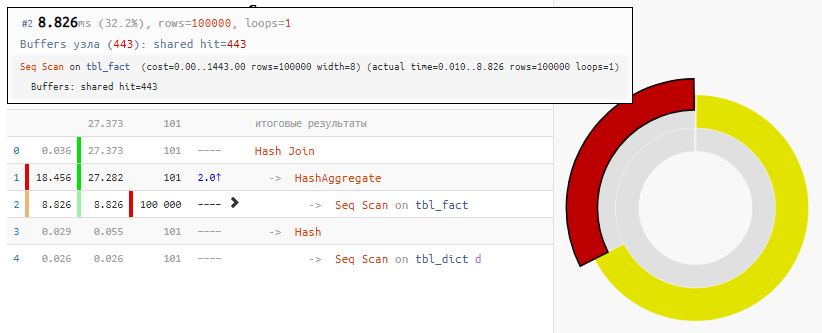
[看explain.tensor.ru]当然,该方法不是通用的,但是对于我们的“常规JOIN”情况
,时间增益是请求的最小修改量的
2倍 -仅仅是由于“空”哈希联接,该联接仅接收100个条目而不是100K条目。
不平等条件
现在让任务复杂化:通过一个标识符连接3个表-主表和两个辅助表以及一些应用程序数据,我们将通过这些表进行过滤。
一个很小但很重要的说明:即使基于对目标任务的“应用”知识,我们已经知道,
第一个表(几乎是 (确定性:3:4),而
第二个 表,几乎 很少 (1:8)将满足条件。 )
我们要从主表和第一个辅助表中选择
100个ID按偶数
且满足所有表条件的 第一条记录 。 表中的所有记录,让我们再次达到100K。
脚本生成器 CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
如所听到的,它是书面的
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
 [看explain.tensor.ru]
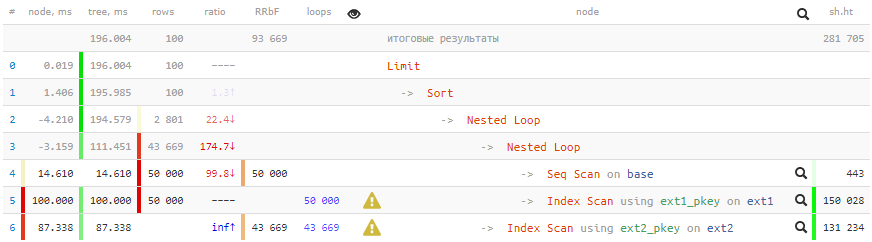
[看explain.tensor.ru]200毫秒及更多2GB数据被抽取-不能很好地记录100条记录!
我们运用创造力
我们使用以下方法来实现加速:
- 首先,我们了解到只有在满足主表的条件 (偶数id) 的情况下,才检查链接表的所有条件才有意义。
- 输出应按base.id排序,为此,此表的主键对我们来说是完美的!
- 我们不需要来自ext2的数据,仅用于验证条件。 这意味着可以将该表的所有工作从JOIN到WHERE部分安全地删除 。 并使用EXISTS进行检查,否则,如果根本没有这样的记录怎么办?
- 仅当成功通过 base和ext2上的其余检查时 , 才需要从ext1检索至少一些数据。 也就是说,与ext1的连接应该在使用base / ext2的所有操作之后进行,这可以使用LATERAL来实现。
- 这样,查询计划人员就不会尝试将ext2上的嵌套验证转换为JOIN( “隐藏在CASE下”子查询)。
SELECT base.* , ext1.* FROM base , LATERAL(
 [看explain.tensor.ru]
[看explain.tensor.ru]当然,请求变得更加复杂,但是值得
赢得13次时间和350次“暴饮暴食”是值得的!
让我再次提醒您,并非所有方法都被使用,并且并非总是如此,但是了解不会是多余的。这也将很有趣: