您在浏览器的地址栏中输入站点的名称,按
Enter键,然后习惯于看到所请求的页面。 很简单:我输入了站点的名称-显示了站点。 但是,出于好奇,我想告诉您浏览器开始接收网站片段时会发生什么情况(是的,网站分为几部分,换句话说,是块状)并显示完整绘制的页面。

浏览器如何工作?
在讲述浏览器如何绘制页面的故事之前,重要的是要了解其组织方式,执行的过程以及执行的级别。 熟悉渲染过程后,我们将多次调用浏览器的组件。 因此,在内部,浏览器看起来像这样:
 用户界面
用户界面是用户看到的全部内容:地址栏,前进/后退按钮,菜单,书签-网站显示区域除外。
浏览器引擎负责用户界面和渲染引擎之间的交互。 例如,单击后退按钮应告诉RE组件有必要绘制先前的状态。
渲染引擎负责显示网页。 根据文件类型的不同,此组件可以解析和呈现HTML / XML和CSS以及PDF。
网络执行对资源的xhr请求,通常,浏览器通过此组件与Internet的其余部分进行通信,包括代理,缓存等。
JS Engine是解析和执行js代码
的地方。
UI Backend用于绘制标准组件,例如复选框,输入,按钮。
数据持久性负责存储本地数据,例如cookie,SessionStorage,indexDB等。
接下来,我们了解所考虑的浏览器组件如何相互交互,并更详细地分析渲染引擎内部发生的情况。 换句话说...
浏览器如何将html转换为屏幕上的像素?
因此,借助网络组件,浏览器开始接收带有块的html文件,通常为8kb,下一步是什么? 然后,您可能已经猜到了解析(过程
规范 )和在组件中渲染此文件的过程-渲染引擎。
重要! 为了提高可用性,浏览器不会等到所有html都加载并解析后再等待。 而是,浏览器立即尝试向用户显示页面(以下,我们将考虑如何)。
解析过程本身如下所示:

解析的结果是
DOM树 。 以以下html为例:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Web Rendering</title> <link rel="stylesheet" href="styles.css"> </head> <body> <div class="wrapper"> <div class="header"> <h1>Hey</h1> </div> <div class="content"> <p> Lorem <span>ipsum</span>. </p> </div> <footer> Contact me </footer> </div> <script src="./code.js"></script> </body> </html>
此类html文件的DOM树如下所示:
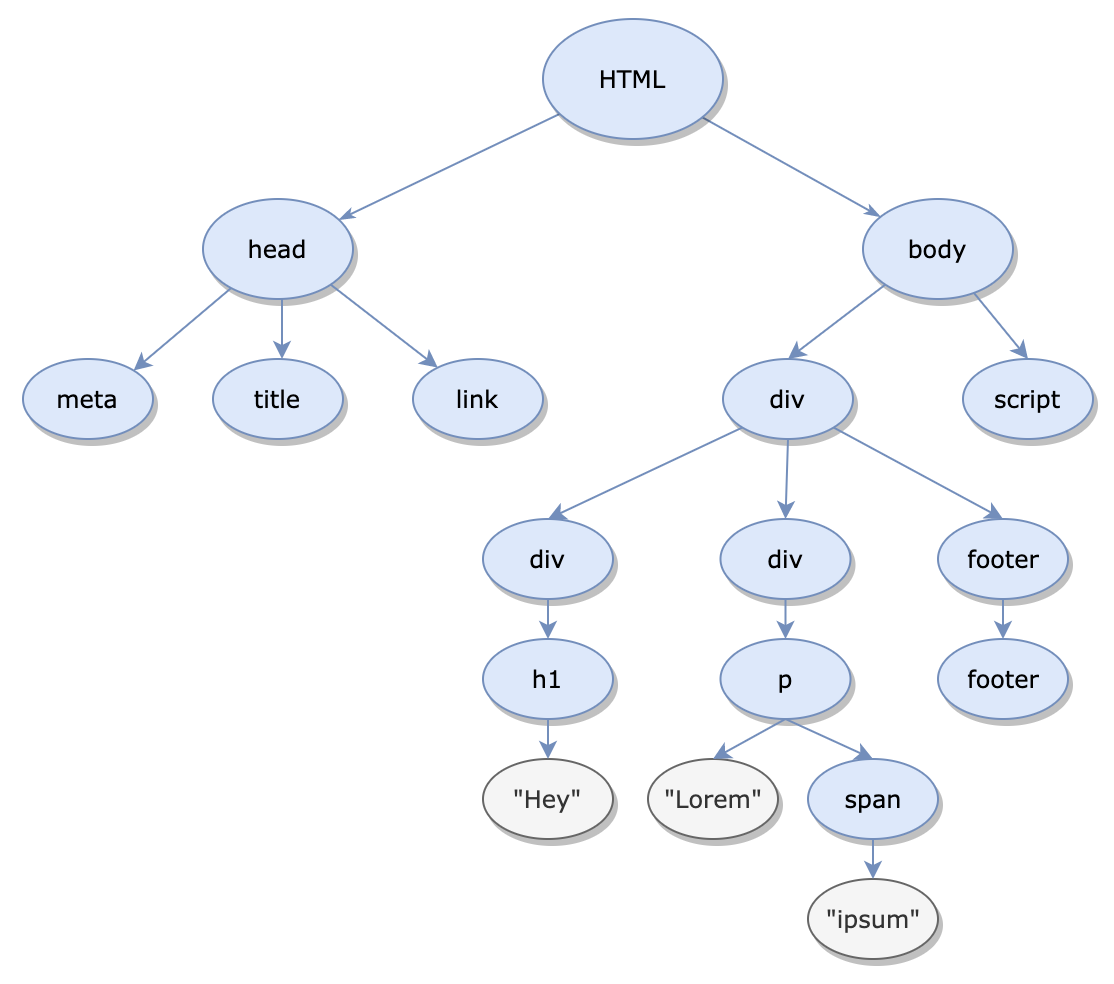
当浏览器解析html文件时,它会遇到包含指向第三方资源链接的标记(
<link>,<script>,<img> 依此类推)-发现这些资源后,就会请求这些资源。
因此,通过向标签的href属性中指定的地址发送请求
<link rel =“ stylessheet”> 浏览器在收到css样式文件后,将解析该文件并构建所谓的
CSS对象模型CSSOM 。
想象一下,我们有这样一个样式表:
body { font-size: 14px; } .wrapper { width: 960px; margin: 0 auto; } .wrapper .header h1 { font-size: 26px; } .wrapper p { color: red; } footer { padding: 20px 0; }
从中我们得到这个
CSSOM :

注意:这里是根据css文件的样式构建的树。 此外,还有html标记中规定的用户代理样式-默认浏览器样式和内联样式。
您可以在
规范中了解有关CSS样式解析算法的更多信息。
现在我们有了
DOM和
CSSOM-第一个回答“什么?”问题,第二个回答“如何?”问题。 如果您认为下一步是结合DOM和CSSOM,那么您绝对正确!
DOM + CSSOM =渲染树。渲染树是一棵可见(!)元素的树,该元素按应在页面上呈现的顺序构建。 请注意,具有css规则显示的元素:不会对显示产生不利影响的其他元素将不在
渲染树中 。
浏览器将构建“渲染树”,以确定确切需要渲染什么以及以什么顺序进行渲染。 渲染树的构造是这样的:从根元素(html)开始,解析器将遍历所有可见元素(跳过链接,脚本,元数据,并通过css元素隐藏),并为每个可见元素从CSSOM中找到相应的css规则。
在firefox引擎中,“渲染树”元素称为帧。 Webkit使用术语渲染器或渲染对象。 渲染对象知道如何将其放置在页面上,并且还包含有关其子对象的信息。 最奇怪的是,如果您查看Webkit的源代码,则可以找到一个名为
RenderObject的类。
继续我们的示例,我们得到了这样的
渲染树 :

目前,我们在某种状态下有一个渲染树-包含有关绘制内容和绘制方式的树。 现在,浏览器必须了解元素的显示位置和尺寸。 计算位置和大小的过程称为
Layout 。
布局是用于确定渲染树中元素的位置和大小的递归过程。 它从它的根渲染对象开始,并递归地向下传递到部分或全部树层次结构,从而计算子渲染对象的几何尺寸。 根元素的位置为(0,0),其大小等于窗口可见部分的大小,即视口的大小。
HTML使用基于流的布局模型,换句话说,在某些情况下,元素的几何尺寸可以通过一次计算(如果稍后出现在流中的元素不影响已通过的元素的位置和大小)。
当需要计算整个树的渲染对象的位置时,布局可以是全局的,而当只需要计算树的一部分时,布局可以是全局的。 例如,在更改字体大小时或在调整大小事件期间,会发生全局布局。 增量布局仅适用于标记为脏的渲染对象。
关于“脏位系统”的几句话。 浏览器使用此系统来优化流程,以免重新计算整个布局。 当添加一个新对象或更改现有渲染对象时,他和他的孩子将被标记为“脏”标志。 如果渲染对象没有更改,但是其子对象已更改或添加,则此渲染对象将标记为“子对象脏”。
在布局过程快要结束时,每个渲染对象都有其自己的位置和大小。
总结一下:浏览器知道绘制什么,如何绘制和在哪里绘制。 因此-它仅用于绘制。 奇怪的是,此过程称为
Paint 。
绘画 -监视像素填充渲染对象属性中指定的颜色,白屏变成作者(开发人员)构想的画面的阶段。 在整个渲染路径中,这是最昂贵的过程(不是以前的过程很便宜)。
与布局过程一样,绘制可以是全局的-树被完全重绘,而增量设置-树被部分重绘。 对于部分重画,渲染对象将其矩形标记为无效。 操作系统将此区域视为需要重绘并引发绘制事件。 同时,浏览器可以合并区域,以便在所有需要的地方立即执行重绘。
调整树元素的大小和位置(布局)和重绘(绘制)是昂贵的过程。 它们在CPU级别运行。 通过开发经常在其中启动这些过程的动态Web应用程序,我们将永远无法获得流畅的动画。
因此,必须有一些东西可以帮助创建具有丰富动画的网站,同时又不会加载CPU并以不到16.6毫秒(60 fps)的速度绘制每一帧。 实际上,浏览器执行了有助于优化网站动态的另一步骤-
复合 (组成)。
合成之前,所有绘制的元素都位于一层(内存层)上。 也就是说,更改某些元素的参数(例如,几何尺寸或位置)将需要重新计算相邻元素的参数。 但是,如果将元素分布在复合层上-更改元素的参数将仅在特定层上引起重新计算,而不会影响其他层上的元素。 因此,就性能而言,此过程最便宜,因此您应尝试进行仅导致复合的更改。
综上所述,我们得到以下呈现网页的过程:
 TLDR
TLDR浏览器接收html文件,对其进行解析并构建DOM。 满足CSS样式,浏览器将它们加载,解析,构建CSSOM并将其与DOM结合在一起,我们得到了渲染树。 剩下的工作就是从“渲染树”中找出元素的布置位置-这是布局任务。 排列完元素后,您可以开始绘制它们-这是绘画任务,是填充屏幕像素的阶段。
动态性
css属性更改时会发生什么? 或者,例如,是否添加了新的dom节点? 如果更改css属性,则全部取决于更改的属性。 只有两个属性可以触发
复合任务-
不透明度和
转换 。 只有这两个属性是最便宜的动画。 例如,更改背景将导致绘制任务(然后是合成),更改显示将首先导致布局,然后绘制,然后合成。 可以在
csstriggers.com上找到由样式更改引起的任务列表。
当向dom树中添加新节点时-很明显,浏览器需要向树中添加新对象,计算其在页面上的位置,计算页面上其他元素的位置(如果它们受到新元素的影响),最后绘制它听起来都非常昂贵。 因此,进行此类操作时,您需要牢记性能,因为并非每个Internet用户都在最新的设备型号上启动Web应用程序。
总而言之,我们检查了浏览器由哪些组件组成,它们如何相互交互以及渲染引擎如何向用户绘制页面。
您可以在chrome devtools中看到以上内容,但是为了不超出文章标题,仅此而已。