每个人都在谈论开发和测试的过程,人员培训,不断增加的动力,但是当一分钟的服务停机花费大量金钱时,这些过程就很少了。 在严格的SLA下进行金融交易时该怎么办? 如何提高系统的可靠性和容错能力,概述开发和测试?

下一次HighLoad ++会议将于2020年4月6日至7日在圣彼得堡举行。 详细信息和门票
在这里 。 11月9日18:00。 HighLoad ++莫斯科2018,德里+加尔各答音乐厅。 摘要和
介绍 。
Evgeny Kuzovlev(以下简称EC): -朋友,您好! 我叫库佐夫列夫·叶夫根尼。 我来自EcommPay,一个特定部门是EcommPay IT,它是一组公司的IT部门。 今天,我们将讨论停机时间-如何避免停机,如何最大程度地减少停机后果(如果无法避免的话)。 主题是:“当一分钟的停机成本高达100,000美元时该怎么办?” 对于我们来说,展望未来,这些数字是可比的。
EcommPay IT做什么?
我们是谁 我为什么站在你的面前? 我为什么有权在这里告诉你一些事情? 在这里,我们将详细讨论什么?

EcommPay集团公司是一家国际收购方。 我们在全球范围内处理付款-在俄罗斯,欧洲和东南亚(世界各地)。 我们有9个办公室,共有500名员工,其中大约一半是IT专家。 我们所做的一切,赚钱的一切,我们自己做的。
我们编写了自己的所有产品(并且我们有很多产品-在大型IT产品系列中,我们有大约16个不同的组件); 我们写自己,我们发展自己。 目前,我们每天进行约一百万笔交易(数以百万计-也许可以这么说)。 我们还只是一家年轻的公司-我们只有大约六岁。
6年前,这两家公司一起成立时就是一家初创公司。 他们被一个主意团结在一起(除了一个主意之外别无其他),我们开始了。 像任何初创公司一样,我们运行得更快。对我们而言,速度比质量更重要。
在某个时候,我们停了下来:我们意识到我们不能再以那样的速度和那样的质量生活了,我们首先需要做质量。 在这一点上,我们决定编写一个正确,可扩展,可靠的新平台。 他们开始编写此平台(他们开始投资,开发,测试),但是在某个时候,他们意识到开发和测试无法达到更高的服务质量水平。
您制作了新产品,将其投入生产,但仍然存在某些地方出了问题。 今天,我们将讨论如何达到新的定性水平(如何获得它,以及我们的经验),如何进行开发和测试? 我们将讨论可用于开发的内容-开发本身可以做什么,可以提供测试以影响质量的内容。
停机时间。 剥削的诫命。
我们今天真正要谈论的主要基石始终是停机时间。 可怕的词。 如果我们有停机时间,那么一切都会对我们不利。 我们正在筹集资金,管理员正在控制服务器-上帝禁止,它不会掉下来,就像那首歌一样。 这就是我们今天要谈论的。

当我们开始改变方法时,我们形成了4条诫命。 它们显示在我的幻灯片上:
这些诫命很简单:

- 快速发现问题。
- 更快地摆脱它。
- 帮助了解原因(后来,对于开发人员而言)。
- 并标准化方法。
我提请您注意第2点。我们摆脱了这个问题,但没有解决。 决定是第二次。 对我们来说,最主要的是保护用户免受此问题的侵害。 它将存在于某个孤立的环境中,但是该环境不会与之接触。 实际上,我们将经历这四类问题(对于某些问题,更详细的描述,对于较不复杂的问题),我将告诉您我们使用的是什么,在解决问题上拥有什么样的经验。
故障排除:它们何时发生以及如何处理?
但是,我们会从无序开始,从第2点开始-如何快速摆脱问题? 有一个问题-我们需要修复它。 “我们该怎么办?”是主要问题。 当我们开始考虑如何解决问题时,我们为自己制定了一些应遵循的故障排除要求。

为了制定这些要求,我们决定问自己一个问题:“我们什么时候有问题”? 事实证明,在以下四种情况下发现了这些问题:

- 硬件故障。
- 外部服务失败。
- 更改软件版本(相同的部署)。
- 爆炸性负荷增长。
我们不会谈论前两个。 硬件故障的解决方法非常简单:您应该重复所有操作。 如果这些是磁盘-磁盘必须在RAID中组装,如果它是服务器-必须复制服务器,如果您具有网络基础结构-您必须放置网络基础结构的第二个副本,即进行复制。 而且,如果您遇到问题,则可以切换到保留容量。 这里很难多说。
第二是外部服务的失败。 对于大多数人来说,该系统根本不是问题,但对我们而言不是。 由于我们处理付款,因此我们是一个聚集在用户(输入卡信息)和银行,支付系统(“ Visa”,“ MasterCard”,“ World”相同)之间的聚合器。 我们的外部服务(支付系统,银行)往往会失败。 我们和您(如果您有此类服务)都不会影响这一点。
那该怎么办? 有两种选择。 首先,如果可以,您必须以某种方式复制此服务。 例如,如果可以的话,我们将流量从一项服务转移到另一项服务:例如,通过Sberbank处理卡,Sberbank遇到问题-我们[有条件地]将流量转移到Raiffeisen。 我们可以做的第二件事是迅速注意到外部服务的故障,因此,我们将在报告的下一部分中讨论响应速度。
实际上,在这四个方面中,我们可以特别地影响软件版本的更改-采取可导致部署方面和负载爆炸性增长方面有所改善的操作。 实际上,我们做到了。 再说一遍...
在这四个问题中,如果有云,就可以立即解决几个问题。 如果您使用的是Microsoft Azhur,Ozone云,请使用Yandex或Mail的云,那么至少硬件故障会成为他们的问题,并且在硬件故障的情况下一切都将立即变好。
我们是一家非标准的公司。 在这里,每个人都在谈论Kubernets,关于云-我们既没有Kubernets,也没有云。 但是我们在许多数据中心中都有装有铁架的机架,我们被迫依靠这种铁架生活,我们被迫为所有事情负责。 因此,在这种情况下,我们将进行讨论。 所以,关于问题。 前两个不在括号内。
更改软件版本。 基地
我们的开发人员无权生产。 为什么这样 但是我们只是通过PCI DSS认证,我们的开发人员根本没有权利进入“产品”。 就这样,期间。 绝对是 因此,开发责任恰好在开发将构建传递到发行版的那一刻结束。

我们拥有的第二个基础是对专业知识的缺乏,这也对我们有很大帮助。 我希望你也一样。 因为如果不是这样,那么您将遇到问题。 如果在正确的时间,正确的位置没有出现这种独特的,没有记录的知识,就会出现问题。 假设您有一个知道如何部署特定组件的人-没有人,他正在休假或生病-就是这样,您遇到了问题。
第三点是我们赖以生存的基础。 我们经历了痛苦,流血,流泪来到了他身边-我们得出的结论是,我们的任何产品都包含错误,即使没有错误也是如此。 我们为自己决定了这一点:当我们部署某些东西时,当我们将某些东西放入产品中时-我们的构建有错误。 我们已经形成了系统必须满足的要求。
软件版本变更要求
其中有三个要求:

- 我们必须快速回滚部署。
- 我们必须将部署失败的影响降到最低。
- 而且我们需要能够快速陷入并行。
按顺序! 怎么了 因为,首先,在部署新版本时,速度并不重要,但是对于您来说很重要,如果出现问题,请快速回滚并减少影响。 但是,如果生产中有一组版本,但事实证明存在错误(例如头上积雪,没有部署,但包含错误)-后续部署的速度对您很重要。 为了满足这些要求我们做了什么? 我们采用这种方法:
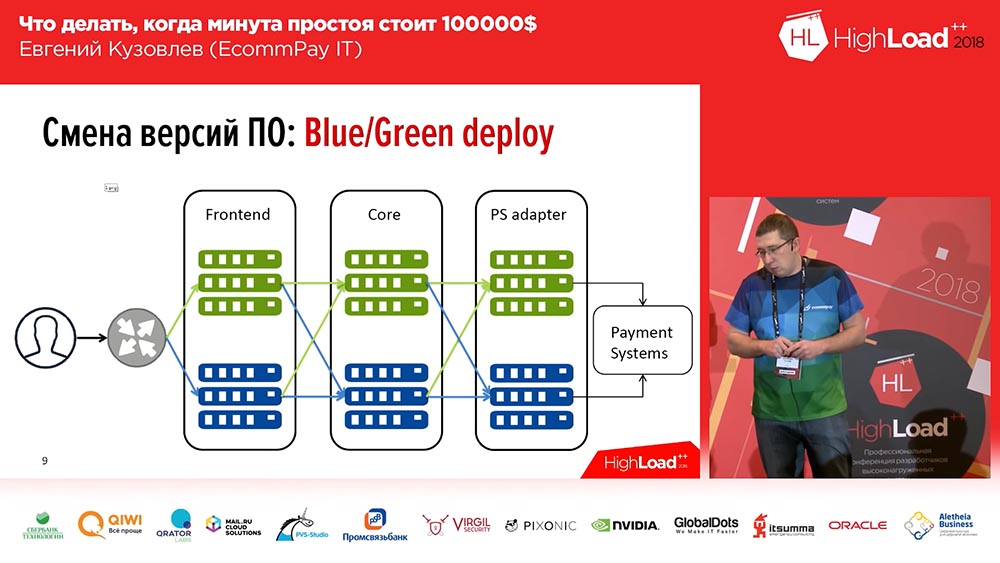
众所周知,我们甚至还没有发明过-这是Blue / Green部署。 这是什么 您必须为安装了应用程序的每组服务器都有一个副本。 副本是“热”的:没有流量,但是可以随时将此流量发送到该副本。 此副本包含以前的版本。 在部署时,您会将代码部署到非活动副本。 然后将部分流量(或全部流量)切换到新版本。 因此,为了将流量从旧版本更改为新版本,您只需执行一项操作:您需要在上游更改平衡器,并改变方向-从上游到另一种。 这非常方便,解决了快速切换,快速回滚的问题。
在这里,第二个问题的解决方案是最小化:您可以添加一条新行,在一条包含新代码的行中仅添加部分流量(例如2%)。 而这2%-不是100%! 如果在不成功的部署过程中丢失了100%的流量-这是令人恐惧的,如果丢失2%的流量-这是令人不愉快的,但并不可怕。 而且,用户很可能甚至不会注意到这一点,因为在某些情况下(不是全部),同一用户通过按F5键将被带到另一个有效版本。
蓝色/绿色部署。 路由选择
而且,并非所有事情都那么简单“蓝/绿部署” ...我们所有的组件都可以分为三类:
- 这是前端(我们的客户看到的付款页面);
- 处理核心;
- 用于与支付系统配合使用的适配器(银行,万事达卡,Visa ...)。
有一个细微差别-细微差别是线之间的路由。 如果仅切换100%的流量,就不会出现这些问题。 但是,如果您要切换2%,问题就开始了:“该怎么做?”额头上最简单的事情是:您可以在nginx中随机选择Round Robin,剩下的还有2%,即98% -在右边 但这并不总是合适的。
例如,此处,用户在一个以上的请求中与系统进行交互。 这是正常的:2、3、4、5个查询-您的系统可能相同。 如果对您来说重要的是,所有用户请求都到达第一个请求所在的同一行,或者(第二时刻)所有用户请求都在切换之后进入新的行(他可以在切换之前更早地开始使用系统,)那么这种随机分布不适合您。 然后有以下选项:

第一个选项,最简单-基于客户端的基本参数(IP哈希)。 您有一个IP,并且按IP从右到左共享。 然后,当部署时,我所描述的第二种情况将为您工作,用户可能已经开始使用您的系统,并且从部署的那一刻起,所有请求都将转到新的一行(例如同一行)。
如果由于某种原因这不适合您,并且您需要将请求发送到用户的主要,亲密请求所在的行,那么您有两个选择...
第一种选择:您可以使用付费的Nginx +。 有一个粘性会话机制,根据用户的初始请求,该机制将会话公开给用户并将其绑定到特定的上游。 在会话有效期内的所有后续用户请求将转到设置会话的同一上游。
这不适合我们,因为我们已经有nginx normal了。 切换nginx +并不是说它很昂贵,这对我们来说有点痛苦,不是很正确。 例如,“ Sticks Sessions”对我们不起作用,原因很简单,因为“ Sticks Sessions”不提供基于“ Eli-or”进行路由的机会。 您可以在此处指定我们要执行的“粘性会话”,例如通过IP或IP和cookie或post参数,但是“ Eli-or”在那里已经很复杂。
因此,我们来到了第四个选项。 我们将nginx用于“类固醇”(这是openresty)-这是与nginx相同的,另外还支持包含last-scripts。 您可以编写一个最后脚本,将其“打开”,然后在用户请求到达时执行该最后脚本。
实际上,我们编写了这样一个脚本,将自己设置为“ openrest”,在此脚本中,我们通过6个不同的参数对“ Or”的串联进行了排序。 根据此参数或该参数的可用性,我们知道用户来到了一页或另一页,一行或另一页。
蓝色/绿色部署。 优缺点
当然,我们可能可以使它更容易一些(使用相同的“ Sticky Sessions”),但是我们仍然有一个细微的差别,不仅用户可以在一次交易的处理范围内与我们进行交互……而且支付系统也可以与我们进行交互:在我们处理交易(通过向支付系统发送请求)之后,我们得到了回调。
并假设如果在电路内部我们可以在所有请求中运行用户的IP地址,并根据IP地址将用户分开,那么我们就不会说相同的“签证”:“老兄,我们是一家复古公司,我们是国际化的(在现场和俄罗斯)。请在其他字段中查看用户的IP地址,您的协议已标准化!” 清除业务,他们不会同意。

因此,对我们来说不合适-我们做到了openresty。 因此,通过路由,我们得到了这样的结果:
蓝色/绿色部署分别具有我所说的优点和缺点。
缺点二:
您需要两倍的服务器,需要两倍的运营资源,并且需要花费两倍的精力来维护所有动物园。
顺便说一下,优点之一是我之前没有提到的另一件事:在负载增加的情况下您有储备。 如果负载爆炸性增长,大量用户落在您身上,那么您只需将第二行包括在50到50的分配中即可,并且您的群集中将立即拥有2台服务器,直到您解决了拥有服务器的问题为止。
如何快速部署?
我们讨论了如何解决最小化和快速回滚的问题,但问题仍然是:“如何快速部署?”

这里是简单的。
- 您必须具有CD系统(连续交付)-没有它,无处。 如果您有一台服务器,则可能会被笔塞住。 当然,我们大约有1500台服务器和1500个句柄-我们可以在这个房间大小的范围内部署一个部门,仅进行部署。
- 部署应该是并行的。 如果部署一致,那么一切都会变糟。 一台服务器是正常的,您将全天部署一千半台服务器。
- 同样,为了加快速度,可能不再需要这样做。 通常在何时部署项目。 您有一个Web项目,有一个前端部分(在其中制作一个Web Pack,npm收集类似的东西),原则上该过程是短暂的-5分钟,但是这5分钟可能很关键。 因此,例如,我们不这样做:我们删除了这5分钟,我们部署了工件。
什么是人工制品? 工件是一个已组装的构建,其中整个组装零件已经完成。 我们将此工件存储在工件的存储中。 我们一次使用了两个这样的存储-Nexus和现在的jFrog Artifactory。)最初使用Nexus是因为我们开始在Java应用程序中实践这种方法(非常适合)。 然后,他们将PHP编写的应用程序的一部分放在那里。 Nexus不再适用,因此我们选择了jFrog Artefactory,它可以使几乎所有东西变得虚假。 我们甚至得出这样一个事实,在这种工件存储中,我们存储了自己的二进制软件包,这些二进制软件包是为服务器收集的。
爆炸负荷增长
我们谈到了更改软件版本。 我们接下来要面对的是爆炸性的负载增长。 在这里我可能理解负载的爆炸性增长并不是一件正确的事...
我们写了一个新的系统-它是面向服务的,时尚漂亮的,到处都是工人,到处都是队列,到处都是异步。 在这样的系统中,数据可以以不同的方式进行。 对于第一笔交易,可以涉及第一,第三,第十名工人,对于第二笔交易,可以涉及第二,第四,第五名。 假设今天是早上,您有一个使用前三个工作程序的数据流,到了晚上,它发生了巨大的变化,所有其他三个工作程序都在使用。
事实证明,您需要以某种方式扩展工作人员,需要以某种方式扩展服务,但同时又要防止资源膨胀。

我们已经确定了自己的要求。 : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

? ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». ? , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
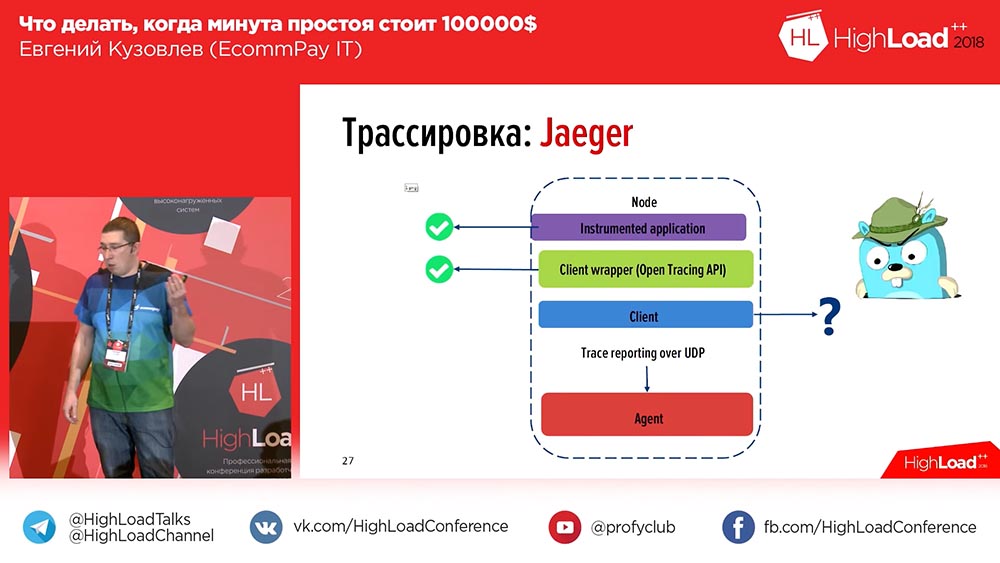
. , , , , «», id- ( ). . 怎么了 , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
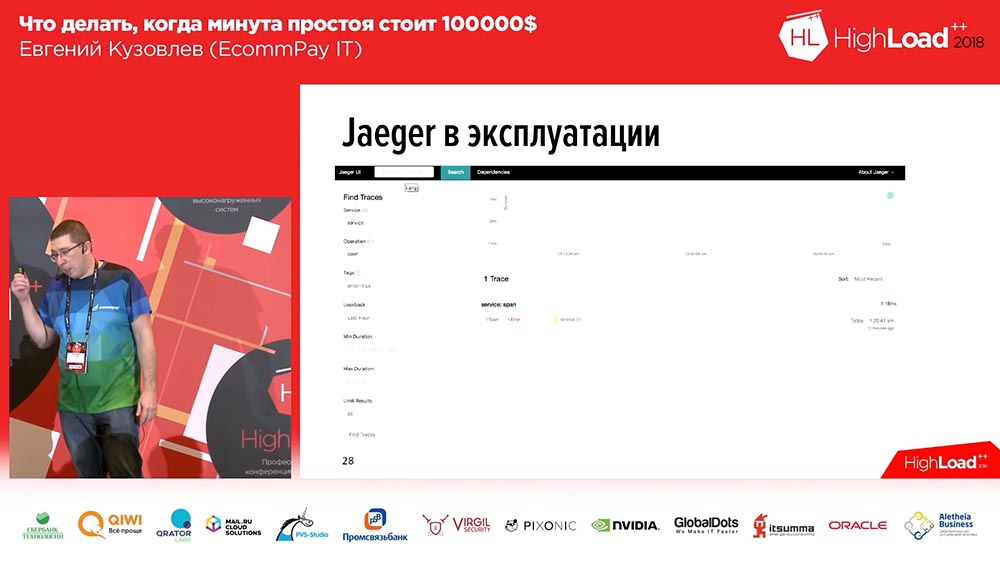
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- 我们有宽容。例如,如果我们在两分钟之内损失了2%的流量,就不会考虑停机时间。原则上,这不属于我们的统计范围。如果百分比或时间更多,我们已经计算在内。
- 而且我们总是写事后报告。无论我们发生什么,在生产现场表现不当的任何情况都将反映在potsortem中。验尸是一个文档,您可以在其中写下发生的事情,解决问题的详细时间安排(这是必填项!),以防止将来发生这种情况。这是必需的,对于后续分析是必需的。
需要考虑什么停机时间?

这一切导致了什么?
这导致在过去的6个月中(我们有一定的稳定性问题,这不适合客户或我们),我们的稳定性指标为99.97。 可以说这不是很多。 是的,我们需要努力。 该指标大约一半是稳定性,而不是我们的稳定性,而是我们的Web应用程序防火墙,它位于我们之前并用作服务,但对客户而言并不重要。
我们学会了晚上睡觉。 终于! 六个月前,我们不知道如何。 关于结果,我要说一句话。 昨晚,关于核反应堆控制系统的精彩报道。 如果编写此系统的人听到了我的声音,请忘记我所说的“ 2%并非停机时间”。 对您来说,即使停机两分钟,停机时间也只有2%!
仅此而已! 您的问题。

关于平衡器和数据库迁移
观众提问(以下简称-B):-晚上好。 非常感谢您提供这样的管理员报告! 这个问题与您的平衡器有关。 您提到您拥有WAF,也就是说,据我了解,您使用某种外部平衡器...
: -不,我们将我们的服务用作平衡器。 在这种情况下,WAF对我们而言仅是DDoS保护工具。
问: -您能谈谈平衡器吗?
EK: -正如我所说,这是openresty中的一组服务器。 现在,我们有5组冗余的冗余服务器,它们分别进行响应……也就是说,一台服务器完全开放,仅代理流量。 因此,要了解我们持有多少流量:我们现在有规则的流量-这是几百兆比特。 他们管理,感觉良好,甚至不紧张。
问: -还有一个简单的问题。 有一个蓝色/绿色部署。 以及您如何处理例如从数据库进行迁移?
EK: -好问题! 看,我们在Blue / Green部署中每行都有单独的行。 也就是说,如果我们谈论的是从工作人员传输到工作人员的事件线,则蓝线和绿线有单独的线。 如果我们在谈论数据库本身,那么我们会尽可能地缩小范围,使所有内容几乎保持一致,数据库中只有一堆事务。 而且我们所有行都有一个交易堆栈。 在这种情况下使用数据库:我们不会将其共享为蓝色和绿色,因为这两个版本的代码都应该知道事务处理过程。
朋友们,我仍然有那么小的奖品可以激励你-一本书。 我需要向她提出最佳问题。
问: -您好。 感谢您的报告。 问题是这样的。 您监视付款,监视与之通信的服务...但是如何监视,以便某人以某种方式进入您的付款页面,进行付款,并且该项目向他贷了钱? 也就是说,您如何监视行军是否可用并接受了您的回叫?
: -在这种情况下,“商人”对我们来说是与支付系统完全相同的外部服务。 我们监视“商人”的响应速度。
关于数据库加密
问: -您好。 我有一个问题。 您有敏感的PCI DSS数据。 我想知道如何将PAN存储在需要放入的队列中? 您是否使用任何加密? 从这里出现了以下第二个问题:在PCI DSS上,有必要在发生更改(管理员被解雇等)的情况下定期重新加密数据库-这种可访问性如何发生?

EK: -很棒的问题! 首先,我们不将PAN存储在队列中。 从原则上讲,我们无权将PAN清晰地存储在任何地方,因此,我们使用特殊服务(我们称其为“ Cademon”)-该服务仅做一件事:它接收消息并发送加密的消息。 并且我们将所有内容都存储在此加密消息中。 因此,对于我们来说,密钥长度在千字节以下,因此它是直接且可靠的。
问: -您现在需要2 KB吗?
EK: -好像昨天是256 ...好吧,还有其他地方?!
因此,这是第一。 其次,现有的解决方案支持重新加密过程-有两对“蛋糕”(密钥)提供了加密的“数据包”(密钥是密钥,dek是加密密钥的派生)。 在启动程序的情况下(定期进行,从3个月到±大约),我们上传了一对新的“蛋糕”,并对数据进行了重新加密。 我们有单独的服务,可以删除所有数据,并以新的方式对其进行加密; 数据存储在密钥标识符旁边,并使用该密钥标识符对其进行加密。 因此,一旦我们使用新密钥对数据进行加密,便会删除旧密钥。
有时您需要手动付款...
问: -也就是说,如果返回某项操作,则用旧密钥解密吗?
EC: -是的。
问: -还有一个小问题。 当发生某种故障,跌倒,事件时,有必要以手动模式推送事务。 有这种情况。
EK: -是的。
问: -您从哪里获得这些数据? 还是您自己带笔去这家商店?
EK: -当然,-我们有一些后台系统,其中包含我们支持的接口。 如果我们不知道交易的状态(例如,在付款系统未响应超时的情况下),则我们不知道先验条件,也就是说,我们只能完全放心地分配最终状态。 在这种情况下,我们会将交易转储为特殊状态以进行手动处理。 第二天早上,当支持人员收到有关此类交易保留在支付系统中的信息后,他们便会在此界面中手动处理它们。

问: -我有几个问题。 其中之一是PCI DSS区域的延续:如何获得其循环日志? 这样的问题是因为开发人员可以在日志中添加任何内容! 第二个问题:如何推出修补程序? 数据库中的笔是一种选择,但是可能有免费的热修复程序-那里的程序是什么? 第三个问题可能与RTO,RPO有关。 您的可用性为99.97,几乎是四个九,但是据我了解,您有第二个数据中心,第三个数据中心和第五个数据中心……您如何处理它们的同步,复制以及其他所有功能?
EK: -让我们从第一个开始。 关于日志的第一个问题是? 当我们写日志时,我们有一个掩盖所有敏感数据的层。 她看着面具和其他领域。 因此,我们的日志带有已经屏蔽的数据和PCI DSS循环。 这是分配给测试部门的常规任务之一。 他们必须检查每个任务,包括他们编写的日志,这是代码审查中的常规任务之一,目的是控制开发人员未编写任何内容。 信息安全部门大约每周一次对此进行定期验证:有选择地在最后一天记录日志,并通过测试服务器中的特殊扫描仪分析器运行日志以检查所有内容。
关于热修复。 这包含在我们的部署计划中。 我们有一个单独的修补程序。 我们相信,我们会在需要时全天候部署修补程序。 一旦版本被组装,一旦运行,就拥有了工件,我们就会从支持人员处召集系统管理员,他将在必要时进行部署。
关于“四个九”。 我们现在拥有的数量确实达到了,因此我们在另一个数据中心寻求了它。 现在我们有了第二个数据中心,并且开始在它们之间进行路由,而跨数据复制中心的问题实际上是一个不小的问题。 我们试图通过不同的方式在适当的时候解决它:我们试图使用相同的“ Tarantula”-它对我们不起作用,我是马上说。 因此,我们得出这样一个事实,我们手动进行“感觉”的排序。 实际上,每个应用程序都处于数据中心之间必要的同步“更改完成”驱动器的异步模式下。
问: -如果您有第二个,那么为什么不拥有第三个呢? 因为还没有人脑裂...
: -我们没有裂脑。 由于每个应用程序都驱动一个多主机,因此对我们来说,请求到达哪个中心都没有关系。 我们已经做好了以下准备:在一个数据中心崩溃(我们躺在上面)的情况下,并且在用户请求切换到另一个数据中心的过程中,我们真的准备失去这个用户; 但它是单位,绝对单位。
问: -晚上好。 感谢您的报告。 您谈到了调试器,该调试器在生产中驱动了一些测试事务。 但是,请告诉我们有关测试交易的信息! 它有多深?
EC: -贯穿整个组件的整个周期。 组件的测试事务和实战事务之间没有区别。 从逻辑的角度来看,这只是系统中的一些单独项目,在该项目上仅跟踪测试事务。
问: -您在哪里切断? 所以Core发送了...
: -在这种情况下,我们在“ Kor”后面进行测试交易...我们拥有诸如路由之类的东西:“ Kor”知道要发送到哪个付款系统-我们将其发送到伪造的付款系统,该系统仅给出http响应,仅此而已。
问: -请告诉我,您是否用一个巨大的整体编写了应用程序,还是将其切成某些服务甚至微服务?
: -我们没有一个整体,当然,我们有一个面向服务的应用程序。 我们开玩笑说我们有一个整体服务-它们确实很大。 将微服务称为这种语言根本没有道理,但是这些是分布式机器工人在其中工作的服务。
如果服务器上的服务受到威胁...
问: -那么我有以下问题。 即使是一个整体,您仍然说您有很多这样的即时服务器,它们在原则上都处理数据,问题是:“如果即时服务器或应用程序之一受到损害,则任何特定的链接他们有任何种类的访问控制吗? 他们中的哪个可以做什么? 与谁联系,获取什么数据?

EK: -当然可以。 安全要求非常严格。 首先,我们拥有开放的数据流量,而端口仅是我们预先预计流量的端口。 如果该组件与5-4-3-2上的数据库通信(例如,“ Muskul”),则只有5-4-3-2和其他端口将为此打开,其他流量方向将不可用。 此外,我们必须了解,在生产中,我们有大约10个不同的安全循环。 而且,即使应用程序受到某种程度的破坏(上帝禁止),攻击者也将无法访问服务器管理控制台,因为这是另一个网络安全区域。
问: -在这种情况下,当您与服务签订合同时,我会更感兴趣-它们可以做什么,他们可以通过哪些“行动”相互联系...在正常流程中,一些特定的服务会询问一个系列,另一个上的“动作”列表。 在正常情况下,他们似乎不求助于他人,他们还有其他责任范围。 如果其中之一受到损害,他是否能够拉出该服务的“行动”?
EK: -我明白。 如果通常情况下通常允许与其他服务器通信,则可以。 根据SLA合同,我们不会监视您仅被允许前三个“操作”,而不允许您执行前四个“操作”。 对于我们来说,这可能是多余的,因为原则上我们为电路提供4级保护系统。 我们更喜欢用轮廓来捍卫,而不是在内部层次上捍卫。
Visa,MasterCard和Sberbank如何运作
问: -我想澄清一下有关将用户从一个数据中心切换到另一个数据中心的情况。 据我所知,“ Visa”和“ MasterCard”在二进制同步协议8583上起作用,有很多不同之处。 我想知道,现在我的意思是转换-是直接“ Visa”和“ MasterCard”还是支付系统,处理?
EK: -取决于混合。 我们在一个数据中心内的混合。
问: -大致来说,您有一个连接点吗?
: -“ 老虎钳 ”和“万事达卡”-是的。 例如,仅由于“ Visa”和“ MasterCard”需要在基础设施上进行相当大的投资才能签订单独的合同才能获得第二对组合。 它们保留在一个数据中心的框架中,但是,上帝禁止,如果连接“ Visa”和“ MasterCard”的数据混合的数据中心死了,那么我们将与“ Visa”和“ MasterCard”建立连接迷路...
问: -如何保留它们? 我知道“签证”原则上只允许一个连接!
EK: -他们自己提供设备。 无论如何,我们收到的设备都是内部冗余的。
问: -是从他们的Connects Orange机架吗?
EC: -是的。
问: -但是在这种情况下:如果您的数据中心消失了,您是否应该进一步使用它? 还是只是交通停滞?
EC: -不。 在这种情况下,我们只需将流量切换到另一个渠道,这当然对我们来说会更昂贵,对客户来说也会更昂贵。 但是流量不会通过我们直接连接到“ Visa”,“ MasterCard”的流量,而是通过传统的“ Sberbank”(非常夸张)。
如果我伤害到Sberbank员工,我深感抱歉。 但是,根据我们的统计数据,Sberbank经常从俄罗斯银行中掉出来。 在不到一个月的时间里,Sberbank并没有发生任何事情。

一点广告:)
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或向您的朋友推荐给开发人员的基于云的VPS, 最低 价格为4.99美元 , 这是我们为您发明的入门级服务器的独特类似物: 关于VPS(KVM)E5-2697 v3(6核)的全部真相10GB DDR4 480GB SSD 1Gbps从$ 19还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
阿姆斯特丹的Equinix Tier IV数据中心的戴尔R730xd便宜2倍吗? 仅在荷兰,我们有2台Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100电视 ! 戴尔R420-2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB-$ 99起! 阅读有关如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?