我们将继续处理GraalVM的工作,这一次,我们翻译了Aleksandar Prokopec撰写的文章“ GraalVM JIT优化的内幕”,该文章最初发表在Medium博客上 。 这篇文章有一些有趣的链接,稍后我们将尝试翻译这些文章。

上次在Medium上,我们研究了与Java HotSpot VM相比GraalVM上的Java Streams API性能问题。 GraalVM具有高性能的特点,在这些实验中,我们将加速度提高了1.7到5倍。 当然,性能提升的具体值将始终取决于您运行的代码和加载数据,因此在做出任何结论之前,您应尝试自己在GraalVM上运行代码。
在本文中,我们将更深入地研究GraalVM的内部,并了解JIT编译是如何发生的。
GraalVM中的JIT优化
让我们看一下GraalVM编译器使用的许多高级优化。 在本文中,我们将仅涉及最有趣的优化及其具体示例。 如果您想更深入地了解,可以在标题为“通过积极的JIT编译使收集操作达到最佳”的工作中对GraalVM编译器优化进行全面概述。
内联
如果您不提前接触组件,那么现代虚拟机中的大多数JIT编译器都会进行内部分析。 这意味着在每个特定的时间点都对一种方法进行了分析。 因此,过程内分析比整个程序的过程间分析要快得多,后者通常在JIT编译器的工作时间内没有时间完成。 在使用过程内优化(例如,一次优化一种方法)的编译器中,最重要的基础优化之一是内联。 内联很重要,因为它有效地增加了方法,这意味着编译器可以看到更多机会来同时优化看似无关的方法中使用的几段代码。
以上一篇文章中的volleyballStars方法为例:
@Benchmark public double volleyballStars() { return Arrays.stream(people) .map(p -> new Person(p.hair, p.age + 1, p.height)) .filter(p -> p.height > 198) .filter(p -> p.age >= 18 && p.age <= 21) .mapToInt(p -> p.age) .average().getAsDouble(); }
在此图中,我们在解析相应的Java字节码之后立即看到了GraalVM中该方法的中间表示(IR)的一部分。

您可以将此IR视为类固醇上的某种抽象语法树 -借助它,一些优化更易于执行。 此IR的工作方式无关紧要,但是如果您想更深入地理解该主题,可以查看一个名为“ Graal IR:可扩展的声明性中间表示”的文档。
这里的主要结论是,由图形的黄色节点和红色线指示的方法的控制流依次执行Stream接口的方法: Stream.filter , Stream.mapToInt , IntStream.average 。 缺少对这些方法的代码的准确了解,编译器无法简化该方法-在此可以进行内联!
称为内联的转换是一件非常容易理解的事情:它只是查找调用方法的位置,并将它们替换为相应内联方法的主体,然后将其嵌入到内部。 内联一部分方法后,让我们看一下volleyballStars方法的IR。 这里仅IntStream.average调用之后的部分:

该图显示对getAsDouble调用(节点号71)已消失。 请注意,从IntStream.average返回的getAsDouble对象的getAsDouble方法(在volleyballStars方法中的最后一次调用)在JDK中定义如下:
public double getAsDouble() { if (!isPresent) { throw new NoSuchElementException("No value present"); } return value; }
在这里,我们可以找到isPresent字段(节点号190, LoadField )的加载并读取value字段。 但是, NoSuchElementException异常没有任何痕迹,也没有其他代码可以引发该异常。
这是因为GraalVM编译器猜测: volleyballStars方法永远不会引发异常。 在getAsDouble编译期间,通常无法获得此知识-可以在程序中的许多不同位置调用它,并且在某些其他情况下,异常仍然有效。 但是,在特定的排球明星方法中,不太可能发生异常,因为潜在的排球明星永远不会为空。 因此,GraalVM删除了分支, FixedGuard插入了FixedGuard一个在违反我们的假设的情况下FixedGuard代码进行优化的节点。 这是一个非常简单的示例,在现实生活中,内联如何帮助其他优化的情况要复杂得多。
我们知道程序调用树通常很深,甚至可能是无止境的。 因此,必须在某些时候停止内联-它对操作时间和内存大小有非常具体的限制。 知道这一点,就很清楚:确定什么以及何时进行内联非常困难。
多态内联
仅当编译器可以确定方法调用操作针对的特定方法时,内联才有效。 但是在Java中,通常有许多间接调用那些方法的实现在静态中是未知的方法,这些方法在运行时使用虚拟调度进行搜索。
例如,采用IntStream.average方法。 它的典型实现如下所示:
@Override public final OptionalDouble average() { long[] avg = collect( () -> new long[2], (ll, i) -> { ll[0]++; ll[1] += i; }, (ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; }); return avg[0] > 0 ? OptionalDouble.of((double) avg[1] / avg[0]) : OptionalDouble.empty(); }
不要让代码的表面简单性欺骗您! 此方法是根据collect调用定义的,神奇之处就在于此。 随着我们深入到collect ,此方法的调用树(例如,调用层次结构)迅速增长。 看看这个图:
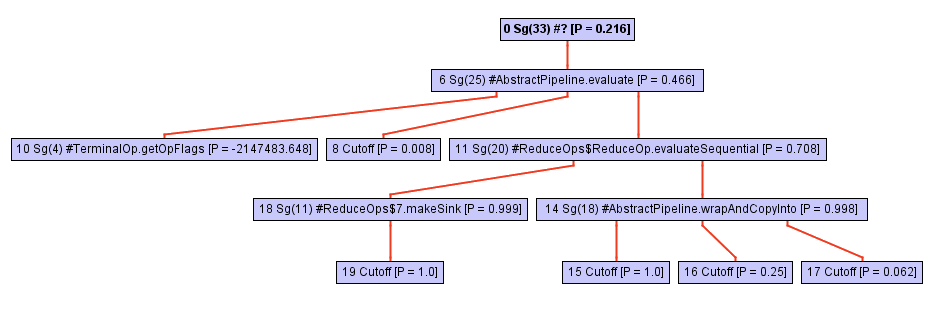
从遍历调用树的过程中的某个点开始,内联器将opWrapSink来自Java opWrapSink框架的opWrapSink调用,这是一种抽象方法:

abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
通常,内联不会走得更远,因为它是间接调用。 特定方法的确定将仅在程序执行期间进行,现在镶嵌程序根本不知道接下来要做什么。
对于GraalVM,会发生其他事情:它为每个间接调用点保存了目标方法类型的配置文件。 此配置文件实质上只是一个表,该表指示每个wrapSink实现的wrapSink 。 在我们的例子中,概要文件知道匿名类中的三种不同实现: ReferencePipeline$2 , ReferencePipeline$3 , ReferencePipeline$4 。 分别以50%,25%和25%的概率调用这些实现。
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
此信息为编译器提供了宝贵的帮助,使您可以生成typeswitch-一个简短的switch ,该switch在运行时检查方法的类型,然后为上述每种情况调用特定的方法。 下图显示了中间视图的一部分,该视图显示typeswitch(三个节点),并检查接收者类型是ReferencePipeline$2 , ReferencePipeline$3还是ReferencePipeline$4某人。 现在,可以将每个InstanceOf检查成功分支中的每个直接调用内联或将一些其他优化与其连接。 如果所有类型均未通过测试,则在Deopt节点中对代码进行非优化(作为替代,您可以运行虚拟调度)。

如果您想更深入地了解多态内联,我建议您参考“虚拟方法的内联”这一主题的经典著作。
局部逃逸分析
让我们回到排球的例子。 请注意,在lambda内部分配给map函数的分配的Person对象中,没有一个逃脱volleyballStars方法的范围。 换句话说,在volleyballStars方法结束时,没有这样的内存区域指向Person类型的对象。 特别是, getHeight值的记录还仅用于高度过滤。
在volleyballStars方法的编译过程中的某个时刻,我们进入下图所示的IR。 从Begin节点-1621开始的块开始于Person对象的分配(在Alloc节点中),该分配使用以1为增量的age字段的值和height字段的先前值初始化。 height字段以前是在LoadField -1539节点中读取的。 分配的结果封装在AllocatedObject -2137中,并发送到accept -1625方法调用。 编译器此刻无法执行任何操作-从他的角度来看,该对象已从volleyballStars方法转义。 ( 译者注:“逃跑一个对象”在英语中称为“逃逸”,因此优化的名称为“逃逸分析” )。

之后,编译器决定内联accept调用-这似乎是合理的。 结果,我们得出以下IR:
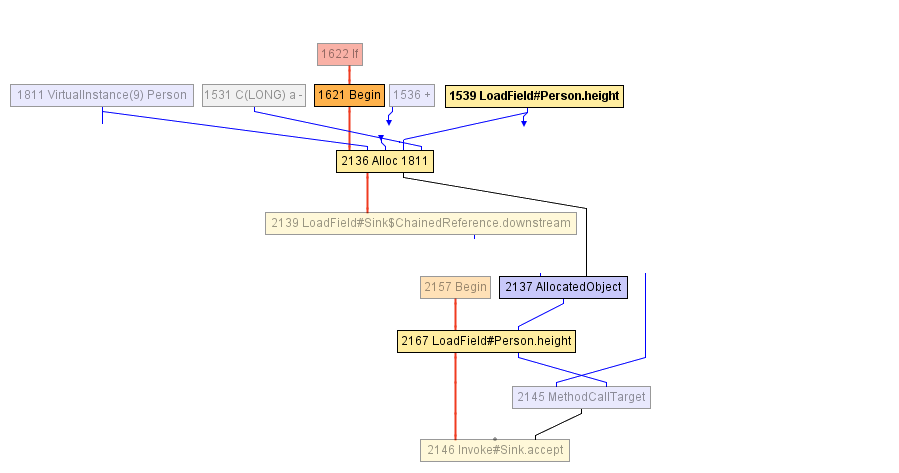
在这里,JIT编译器开始进行部分转义分析:它注意到AllocatedObject仅用于读取height字段(回想起, height仅在过滤条件下使用,请检查高度是否大于198)。 因此,编译器可以重新分配对height -2167字段的读取,以便直接使用先前写入Person对象的节点( Alloc -2136节点),这就是我们的LoadField -1539。 而且,此后的Alloc节点不会转到任何其他节点的输入,因此您可以简单地将其删除-这是无效代码!
实际上,这种优化是volleyballStars示例切换到GraalVM后经历五倍加速的主要原因。 即使不需要所有Person对象并在创建后立即将其丢弃,它们仍需要在堆上分配,它们的内存仍需要初始化。 部分转义分析使您可以消除分配,也可以通过将其移到对象确实耗尽并且发生频率更低的那些代码分支来推迟分配或推迟分配。
在名为Java的部分转义分析和标量替换的论文中,您可以对部分转义分析有更深入的了解。
总结
在本文中,我们研究了三种GraalVM优化:内联,多态内联和部分转义分析。 还有更多不同的优化方法:循环的升级和拆分,路径的重复,全局值的编号,常数的卷积,无效代码的删除,投机执行等。
如果您想了解有关GraalVM工作原理的更多信息,请随时打开发布页面 。 如果要确定GraalVM是否可以加快代码速度,可以下载二进制文件并自己尝试。
来自翻译者:其他材料
在会议上,JPoint和Joker经常谈论GraalVM。 例如,在最后的JPoint 2019上,托马斯·伍尔辛格(Thomas Wuerthinger)(Oracle Labs的研究总监,负责GraalVM)和两位官方技术传播者之一奥列格·谢拉耶夫(Oleg Shelaev)参观了我们。
您可以在我们的YouTube频道上观看这些视频和其他视频:
我们提醒您,下一次JPoint将于2020年5月15日至16日在莫斯科举行,门票已经可以在官方网站上购买。