ClickHouse用户已经知道,它的最大优势是其高速处理分析查询。 但是需要通过可靠的性能测试来确认这种说法。 这就是我们今天要谈的。
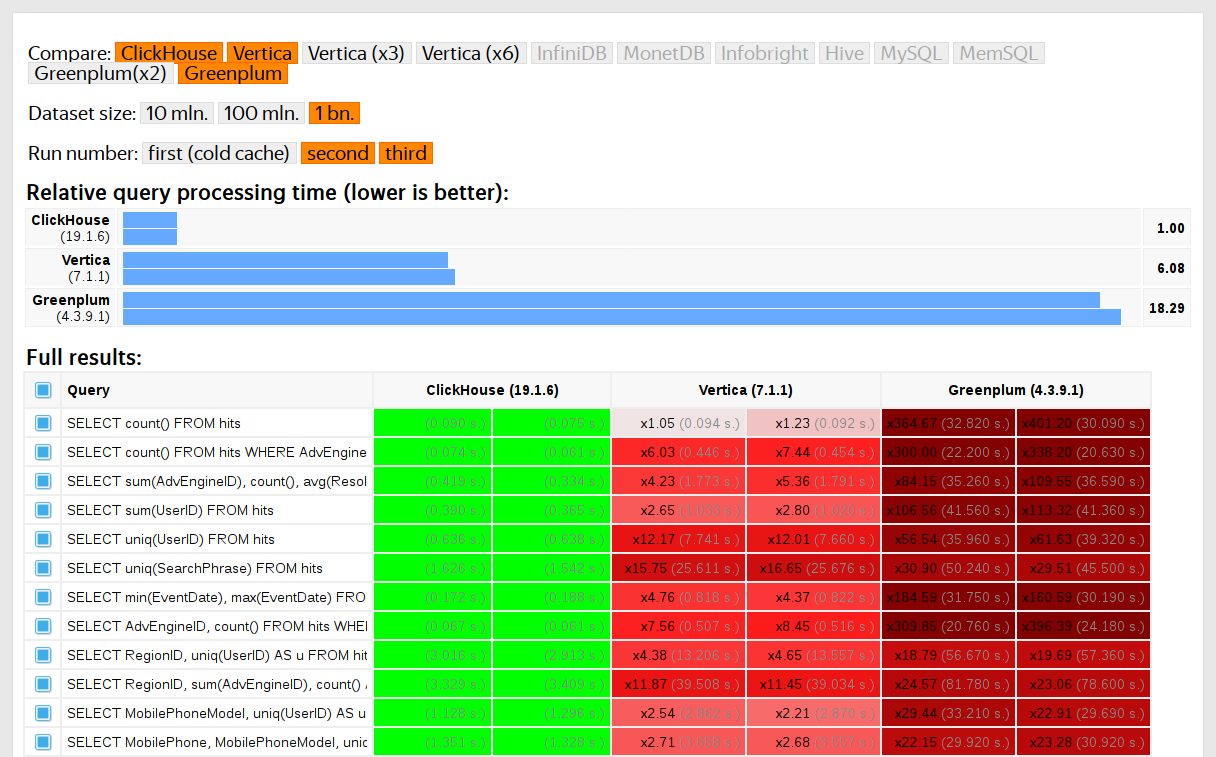
我们于2013年开始运行测试,远远早于该产品作为开源可用。 那时,就像现在一样,我们主要关心的是Yandex.Metrica中的数据处理速度。 自2009年1月以来,我们一直将这些数据存储在ClickHouse中。从2012年开始,部分数据已写入数据库,而部分数据是从
OLAPServer和Metrage转换而来的(Yandex.Metrica以前使用的数据结构)。 为了进行测试,我们从10亿次网页浏览的数据中随机抽取了第一个子集。 Yandex.Metrica当时没有任何查询,因此我们提出了令我们感兴趣的查询,并使用所有可能的方法来过滤,汇总和排序数据。
将ClickHouse的性能与Vertica和MonetDB等类似系统进行了比较。 为避免偏差,测试由未参与ClickHouse开发的一名员工执行,并且直到获得所有结果后,代码中的特殊情况才得以优化。 我们使用相同的方法来获取用于功能测试的数据集。
ClickHouse于2016年作为开源发布后,人们开始质疑这些测试。
私人数据测试的缺点
我们的性能测试:
- 由于它们使用无法发布的私人数据,因此无法独立复制。 出于相同的原因,某些功能测试不适用于外部用户。
- 需要进一步发展。 测试集需要大大扩展,以隔离系统各个部分的性能变化。
- 不要在每个提交的基础上运行,也不要针对单个请求请求运行。 外部开发人员无法检查其代码是否有性能下降。
我们可以通过淘汰旧测试并根据开放数据(例如
美国的飞行数据和
纽约的出租车行程)编写新测试来解决这些问题。 或者我们可以使用诸如TPC-H,TPC-DS和
Star Schema Benchmark之类的基准测试 。 缺点是该数据与Yandex.Metrica数据有很大不同,我们宁愿保留测试查询。
为什么使用真实数据很重要
性能只能在生产环境中的真实数据上进行测试。 让我们看一些例子。
例子1假设您使用均匀分布的伪随机数填充数据库。 尽管数据压缩对于分析数据库是必不可少的,但是在这种情况下数据压缩将无法正常工作。 对于选择正确的压缩算法以及将其集成到系统中的正确方法的挑战,没有万能的解决方案,因为数据压缩需要在压缩和解压缩的速度以及潜在的压缩效率之间进行折衷。 但是无法压缩数据的系统肯定会失败。 如果您的测试使用均匀分布的伪随机数,则将忽略此因素,结果将失真。
底线:测试数据必须具有实际的压缩率。
在上
一篇文章中,我介绍了ClickHouse数据压缩算法的优化。
例子2假设我们对这个SQL查询的执行速度感兴趣:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
这是Yandex.Metrica的典型查询。 什么影响处理速度?
- 如何执行GROUP BY。
- 哪种数据结构用于计算uniq聚合函数。
- uniq函数有多少个不同的RegionID以及每个状态需要多少RAM。
但是另一个重要因素是,数据量在区域之间分布不均。 (它可能遵循幂定律。我将分布放在对数-对数图上,但不能肯定地说。)如果是这种情况,那么使用较少值的uniq聚合函数的状态就很重要很少的记忆。 当有很多不同的聚合密钥时,每个字节都非常重要。 我们如何获得具有所有这些属性的生成数据? 显而易见的解决方案是使用实际数据。
许多DBMS都以大约COUNT(DISTINCT)的形式实现HyperLogLog数据结构,但是它们都无法很好地工作,因为该数据结构使用固定数量的内存。 ClickHouse的功能可以
结合使用
三种不同的数据结构 ,具体取决于数据集的大小。
底线:测试数据必须足够好地表示真实数据的分布特性,这意味着基数(每列不同值的数量)和跨列基数(跨几个不同列计算的不同值的数量)。
例子3与其测试ClickHouse DBMS的性能,不如使用哈希表之类的更简单的方法。 对于哈希表,必须选择正确的哈希函数。 这对于std :: unordered_map并不重要,因为它是基于链接的哈希表,并且素数用作数组大小。 GCC和Clang中的标准库实现将普通的哈希函数用作数字类型的默认哈希函数。 但是,当我们寻求最大速度时,std :: unordered_map不是最佳选择。 使用开放地址哈希表,我们不能仅使用标准哈希函数。 选择正确的哈希函数成为决定因素。
使用不考虑哈希函数的随机数据来查找哈希表性能测试很容易。 即使忽略了使用的数据结构,也有很多哈希函数测试侧重于计算速度和某些质量标准。 但是事实是哈希表和HyperLogLog需要不同的哈希函数质量标准。
您可以在
“哈希表如何在ClickHouse中工作” (以俄语表示)中了解更多信息。 该信息有些过时,因为它不包括
Swiss Tables 。
挑战赛
我们的目标是获得与Yandex.Metrica数据具有相同结构的测试性能数据,该数据具有对基准测试很重要的所有属性,但这种方式应确保在此数据中没有任何真实的网站用户。 换句话说,数据必须匿名并且仍然保留:
- 压缩比。
- 基数(不同值的数量)。
- 几个不同列之间的相互基数。
- 可用于数据建模的概率分布的属性(例如,如果我们认为区域是根据幂定律分布的,则指数(分布参数)对于人工数据和真实数据应该大致相同)。
我们如何获得相似的数据压缩率? 如果使用LZ4,则二进制数据中的子字符串必须以大约相同的距离重复,并且重复的长度必须近似相同。 对于ZSTD,每个字节的熵也必须重合。
最终目标是创建一个公共可用的工具,任何人都可以使用它来匿名化其数据集以进行发布。 这将使我们能够调试和测试类似于生产数据的其他人的数据的性能。 我们还希望生成的数据有趣。
但是,这些是非常宽松定义的要求,我们不打算为此任务编写正式的问题说明或规范。
可能的解决方案
我不想听起来像这个问题特别重要。 它实际上从未包含在计划中,也没有人打算进行计划。 我只是一直希望某个想法会在某天出现,突然间我心情会好起来,能够将其他一切推迟到以后。
显式概率模型
第一个想法是获取表中的每一列,并找到对其进行建模的概率分布系列,然后根据数据统计信息(模型拟合)调整参数,并使用结果分布生成新数据。 具有预定义种子的伪随机数生成器可用于获得可重现的结果。
马尔可夫链可用于文本字段。 这是可以有效实施的熟悉模型。
但是,这需要一些技巧:
- 我们要保留时间序列的连续性。 这意味着对于某些类型的数据,我们需要对相邻值之间的差异进行建模,而不是对值本身进行建模。
- 为了建模列的“联合基数”,我们还必须显式反映列之间的依赖关系。 例如,每个用户ID通常只有很少的IP地址,因此要生成IP地址,我们将使用用户ID的哈希值作为种子,并添加少量其他伪随机数据。
- 我们不确定如何表达同一用户经常在大约同一时间访问具有匹配域的URL的依赖性。
所有这些都可以用C ++“脚本”编写,并使用硬编码的形式分发和依赖。 但是,马尔可夫模型是从统计量与平滑和添加噪声的组合中获得的。 我开始写这样的脚本,但是在为十列编写了显式模型后,它变得无聊得令人难以忍受-Yandex.Metrica中的“ hits”表在2012年就有100多个列。
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
这种方法是失败的。 如果我再努力一点,也许脚本现在就可以准备好了。
优点:
缺点:
而且,我更喜欢可以用于Yandex.Metrica数据以及混淆任何其他数据的更通用的解决方案。
无论如何,都可以改进该解决方案。 无需手动选择模型,我们可以实施模型目录并在模型中选择最佳模型(最佳拟合加某种形式的正则化)。 也许我们可以将Markov模型用于所有类型的字段,而不仅仅是文本。 数据之间的依赖关系也可以自动提取。 这将需要计算列之间的
相对熵 (信息的相对数量)。 一个更简单的替代方法是计算每对列的相对基数(类似“固定值B平均有多少个A的不同值”)。 例如,这将使URLDomain完全取决于URL,而反之则不然。
但是我也拒绝了这个想法,因为要考虑的因素太多了,编写起来会花费很长时间。
神经网络
正如我已经提到的,该任务在优先级列表中并不高-甚至没有人考虑过尝试解决它。 但是,幸运的是,我们的同事伊凡·普齐列夫斯基(Ivan Puzirevsky)在高等经济学院任教。 他问我是否有任何有趣的问题可以作为适合他的学生的论文主题。 当我提供给他这个东西时,他向我保证了它的潜力。 因此,我把这个挑战交给了一个“陌生人”谢里夫(Sharif)(尽管他确实必须签署了一份保密协议才能访问数据)。
我与他分享了我的所有想法,但强调指出,如何解决问题没有任何限制,一个不错的选择是尝试使用我不了解的方法,例如使用LSTM生成数据文本转储。 在遇到文章
“递归神经网络的不合理有效性”之后,这似乎很有希望。
第一个挑战是我们需要生成结构化数据,而不仅仅是文本。 但是还不清楚递归神经网络是否可以生成具有所需结构的数据。 有两种解决方法。 第一种解决方案是使用单独的模型来生成结构和“填充物”,而仅使用神经网络来生成值。 但是这种方法被推迟了,然后再也没有完成。 第二种解决方案是简单地将TSV转储生成为文本。 经验表明,文本中的某些行与结构不匹配,但是在加载数据时这些行可能会被丢弃。
第二个挑战是递归神经网络生成数据序列,因此数据依存关系必须遵循序列的顺序。 但是在我们的数据中,列的顺序可能与它们之间的依赖关系相反。
我们没有采取任何措施来解决此问题。
随着夏天的临近,我们有了第一个可以工作的Python脚本来生成数据。 乍看之下,数据质量似乎不错:

但是,我们确实遇到了一些困难:
- 该模型的大小约为1 GB。 我们试图为大小为数GB的数据创建模型(作为开始)。 所得模型如此之大的事实引起了人们的关注。 是否可以提取经过训练的真实数据? 不太可能。 但是我对机器学习和神经网络了解不多,而且我还没有阅读过该开发人员的Python代码,因此如何确定? 当时有几篇文章发表有关如何压缩神经网络而不损失质量的文章,但尚未实现。 一方面,这似乎不是一个严重的问题,因为我们可以选择不发布模型,而只发布生成的数据。 另一方面,如果发生过度拟合,则生成的数据可能包含源数据的某些部分。
- 在具有单个CPU的计算机上,数据生成速度约为每秒100行。 我们的目标是至少产生十亿行。 计算表明,这不会在论文答辩日期之前完成。 使用额外的硬件没有任何意义,因为目标是制造一个任何人都可以使用的数据生成工具。
Sharif试图通过比较统计数据来分析数据的质量。 除其他事项外,他计算了源数据和生成的数据中出现的不同字符的频率。 结果令人震惊:最常见的字符是Ð和Ñ。
不过,不必担心Sharif。 他成功地为自己的论文辩护,然后我们高兴地忘记了整件事。
压缩数据的变异
假设问题陈述已简化为一点:我们需要生成与源数据具有相同压缩率的数据,并且数据必须以相同的速度解压缩。 我们怎样才能做到这一点? 我们需要直接编辑压缩数据字节! 这使我们能够在不更改压缩数据大小的情况下更改数据,并且一切都会快速进行。 我想立即尝试一下这个想法,尽管事实上它解决的问题与我们开始时所遇到的问题不同。 但这就是事实。
那么我们如何编辑压缩文件? 假设我们只对LZ4感兴趣。 LZ4压缩数据由序列组成,这些序列依次是未压缩字节(文字)的字符串,后跟匹配副本:
- 文字(按原样复制以下N个字节)。
- 匹配的最小重复长度为4(重复M个文件中的N个字节)。
源数据:
Hello world Hello 。
压缩数据(任意示例):
literals 12 "Hello world " match 5 12 。
在压缩文件中,我们按原样保留“ match”,并在“ literal”中更改字节值。 结果,在解压缩后,我们得到一个文件,其中所有重复序列(至少4个字节长)也以相同的距离重复,但是它们由一组不同的字节组成(基本上,修改后的文件不包含单个字节)从源文件获取的字节)。
但是,如何更改字节? 答案并不明显,因为除了列类型外,数据还具有我们希望保留的内部隐式结构。 例如,文本通常以UTF-8编码存储,我们希望生成的数据也为有效的UTF-8。 我开发了一种简单的启发式方法,其中涉及满足多个条件:
- 空字节和ASCII控制字符保持原样。
- 一些标点符号保持原样。
- ASCII会转换为ASCII,对于其他所有内容,最高有效位都将保留(或为不同的UTF-8长度写入一组明确的“ if”语句)。 在一个字节类中,随机地统一选择一个新值。
- 像
https://这样的片段会保留下来,否则看起来有点傻。
这种方法的唯一警告是数据模型是源数据本身,这意味着它无法发布。 该模型仅适合于生成不大于源的数据量。 相反,先前的方法提供了允许生成任意大小的数据的模型。
URL的示例:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
结果是肯定的,数据很有趣,但是有些不正确。 URL保持相同的结构,但是在某些URL中,识别“ yandex”或“ avito”(在俄罗斯颇受欢迎的市场)太容易了,因此我创建了一种启发式算法,可以交换一些字节。
还有其他问题。 例如,敏感信息可能以二进制表示形式存在于FixedString列中,并且可能包含我决定保留的ASCII控制字符和标点符号。 但是,我没有考虑数据类型。
另一个问题是,如果列以“长度,值”格式存储数据(这是String列的存储方式),如何确保突变后长度保持正确? 当我尝试解决此问题时,我立即失去了兴趣。
随机排列
不幸的是,这个问题没有解决。 我们进行了一些实验,但情况变得更糟。 剩下的唯一一件事就是无所事事,随意逛网上,因为魔术消失了。 幸运的是,我碰到了一个页面,该页面
解释了渲染游戏《 Wolfenstein 3D》中主要角色死亡
的算法 。

动画确实做得很好-屏幕上充满了鲜血。 本文解释说,这实际上是一个伪随机排列。 一组元素的随机排列是该集合的随机选取的双射(一对一)变换,或者是每个派生元素都恰好对应一个原始元素的映射(反之亦然)。 换句话说,这是一种随机迭代数据集所有元素的方法。 这正是图中所示的过程:每个像素以随机顺序填充,没有任何重复。 如果我们仅在每个步骤中选择一个随机像素,那么到达最后一个像素将花费很长时间。
该游戏使用一种非常简单的伪随机置换算法,称为线性反馈移位寄存器(
LFSR )。 与伪随机数生成器类似,通过密钥进行参数设置后,随机排列或它们的族可以在密码学上很强。 这正是我们进行数据转换所需要的。 但是,细节可能比较棘手。 例如,使用预定的密钥和初始化向量将N字节加密为N字节的加密强度较高的加密似乎可以用于一组N字节字符串的伪随机排列。 确实,这是一对一的转换,而且似乎是随机的。 但是,如果我们对所有数据使用相同的转换,则结果可能易于进行密码分析,因为多次使用相同的初始化向量和键值。 这类似于分组密码的
电子密码
本操作模式。
获得伪随机排列的可能方法是什么? 我们可以进行简单的一对一转换,并构建一个看起来随机的复杂函数。 以下是一些我最喜欢的一对一转换:
- 用二进制补码算术乘以奇数(如大质数)。
- Xorshift:
x ^= x >> N - CRC-N,其中N是参数中的位数。
例如,三个乘法和两个xorshift运算用于
murmurhash终结器。 此操作是伪随机排列。 但是,我应该指出,哈希函数不必是一对一的(即使是N位到N位的哈希)。
或者这是来自Jeff Preshing网站的
基本数论的另一个有趣
示例 。
我们如何使用伪随机排列来解决我们的问题? 我们可以使用它们来转换所有数字字段,以便我们可以保留字段的所有组合的基数和互基数。 换句话说,COUNT(DISTINCT)将返回与转换之前相同的值,并且将返回任何GROUP BY。
值得注意的是,保留所有基数与我们数据匿名化的目标有些矛盾。 假设有人知道站点会话的源数据包含一个访问过10个不同国家/地区站点的用户,并且他们想在转换后的数据中找到该用户。 转换后的数据还显示,用户访问了来自10个不同国家/地区的网站,从而可以轻松缩小搜索范围。 即使他们知道用户被转换成什么,也不会很有用,因为所有其他数据也都已转换,因此他们将无法弄清楚用户访问了哪些站点或其他任何内容。 但是这些规则可以应用于链条中。 例如,如果某人知道我们数据中最常出现的网站是Yandex,而Google位居第二,那么他们可以使用排名来确定哪些转换后的站点标识符实际上是Yandex和Google。 对此并没有什么奇怪的,因为我们正在处理一个非正式的问题说明,并且我们正试图在数据匿名化(隐藏信息)和保留数据属性(信息公开)之间找到平衡。 有关如何更可靠地处理数据匿名化问题的信息,请阅读
本文 。
除了保留值的原始基数,我还希望保留值的数量级。 我的意思是,如果源数据包含的数字小于10,那么我希望转换后的数字也要小。 我们怎样才能做到这一点?
例如,我们可以将一组可能的值划分为大小类,然后分别在每个类中执行置换(保持大小类)。 最简单的方法是将最接近的2的幂或数字中最高有效位的位置作为大小类(这是同一件事)。 数字0和1将始终保持原样。 数字2和3有时将保持原状(概率为1/2),有时将被交换(概率为1/2)。 数字集1024。2047将映射到1024中的一个! (阶乘)变体,等等。 对于已签名的数字,我们将保留其标志。
是否需要一对一的功能也令人怀疑。 我们可能只可以使用加密功能强的哈希函数。 转换不会是一对一的,但是基数将接近相同。
但是,我们确实需要密码学上很强的随机置换,因此,当我们定义密钥并使用该密钥导出置换时,在不知道密钥的情况下很难从重新排列的数据中还原原始数据。
有一个问题:除了对神经网络和机器学习一无所知之外,对于密码学,我也一无所知。 那只剩下我的勇气。 我仍在阅读随机网页,并在
Hackers News上找到了Fabien Sanglard页面上的讨论的链接。 它链接到Redis开发人员Salvatore Sanfilippo的
博客文章 ,该文章讨论了使用一种奇妙的通用方法来获得随机排列,称为
Feistel网络 。
Feistel网络是迭代的,由回合组成。 每个回合都是一次了不起的转换,使您可以从任何功能中获得一对一功能。 让我们看看它是如何工作的。
- 参数的位分为两半:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - 右半部分代替左半部分。 我们将XOR的结果放在左半部分的初始值上,并将函数的结果应用于右半部分的初始值,如下所示:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
还有一种说法是,如果我们对F使用加密强度高的伪随机函数并至少进行4次Feistel回合,我们将获得加密强度高的伪随机置换。
这就像一个奇迹:我们采用了一个基于数据生成随机垃圾的函数,将其插入Feistel网络,现在我们有了一个基于数据生成随机垃圾的函数,但是它是可逆的!
Feistel网络是几种数据加密算法的核心。 我们要做的是像加密一样的东西,只是它真的很糟糕。 这有两个原因:
- 我们将以相同的方式独立加密单个值,类似于电子密码本操作模式。
- 我们正在存储有关数量级(最接近的2的幂)和值的符号的信息,这意味着某些值完全不变。
这样,我们就可以在保留所需属性的同时混淆数字字段。 例如,在使用LZ4之后,压缩率应保持近似相同,因为源数据中的重复值将在转换后的数据中重复,并且彼此之间的距离相同。
马尔可夫模型
文本模型用于数据压缩,预测输入,语音识别和随机字符串生成。 文本模型是所有可能字符串的概率分布。 假设我们对人类曾经写过的所有书籍的文本都有一个假想的概率分布。 为了生成一个字符串,我们只需要在这个分布中取一个随机值,然后返回结果字符串(人类可以写一本随机书)。 但是,我们如何找出所有可能的字符串的概率分布?
首先,这将需要太多信息。 有256 ^ 10个可能的字符串,它们的长度为10个字节,并且显式地写入具有每个字符串概率的表将花费大量的内存。 其次,我们没有足够的统计数据来准确评估分布。
这就是为什么我们使用从粗略统计中获得的概率分布作为文本模型的原因。 例如,我们可以计算出每个字母出现在文本中的概率,然后通过选择具有相同概率的每个下一个字母来生成字符串。 这个原始模型可以工作,但是字符串仍然非常不自然。
为了稍微改善模型,如果在字母N之前加上字母,则我们也可以利用字母出现的条件概率。 N是预设常数。 假设N = 5,我们正在计算字母“ e”出现在字母“ compr”之后的概率。 该文本模型称为Order-N Markov模型。
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...让我们看看
Hay Kranen网站上的Markov模型如何工作。 与LSTM神经网络不同,这些模型仅对固定长度N的较小上下文具有足够的内存,因此它们会生成有趣的,荒谬的文本。 马尔可夫模型还用于生成垃圾邮件的原始方法中,并且可以通过对不适合该模型的统计信息进行计数,轻松地将生成的文本与真实文本区分开。 有一个优点:马尔可夫模型的工作速度比神经网络快得多,这正是我们所需要的。
标题示例(由于使用了数据,我们的示例使用土耳其语):
Hyunday Butter'dan anket shluha-Politika headmanşetleri| Pinkoi STALKER BOXERÇiftede书-YanudistkarışmanlıMıKanal | Pinkoi League el Digitalika Haberler Haberleri-Haberlerisi-配有Centry'ler Neden的酒店babah.com
我们可以根据源数据计算统计信息,创建马尔可夫模型,并由此生成新数据。 请注意,该模型需要进行平滑处理以避免泄露有关源数据中稀有组合的信息,但这不是问题。 我使用从0到N的模型组合。如果对于N阶模型的统计量不足,则使用N − 1模型。
但是我们仍然希望保留数据的基数。 换句话说,如果源数据具有123456个唯一URL值,则结果应具有大约相同数量的唯一值。 我们可以使用确定性初始化的随机数生成器来实现此目的。 最简单的方法是使用哈希函数,并将其应用于原始值。 换句话说,我们得到一个由原始值明确确定的伪随机结果。
另一个要求是,源数据可能具有许多不同的URL,这些URL以相同的前缀开头但不相同。 例如:
https://www.yandex.ru/images/cats/?id=xxxxxx :
https://www.yandex.ru/images/cats/?id=xxxxxx 。 我们希望结果也具有全部以相同前缀开头但URL不同的URL。 例如:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx 。 作为使用Markov模型生成下一个字符的随机数生成器,我们将从指定位置的8个字节的移动窗口中获取哈希函数(而不是从整个字符串中获取)。
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...事实证明这正是我们所需要的。 这是页面标题的示例:
PhotoFunia-Haber7-Havamükemment.net奥伊纳马克(Oynamak)奥卡(OyunuOynanılmaz)•apród.hukínálatában-RT阿拉伯语
PhotoFunia-Kinobar.Net-4月:Ingyenes | 邮政
PhotoFunia-Peg Perfeo-Castika,SıradışıDeniz定位您的代码,Eminema.tv的父亲/
PhotoFunia-TUT.BY-您的Ayakkanınve儿子Dakika Spor,
PhotoFunia-大型电影摄影棚,Del Meireles offilim,三星DealeXtremeDeğerlerNEWSru.com.tv,Smotri.com移动yapmak Okey
PhotoFunia 5 | Galaxy,gt,dupăce肛门bilgi yarak Ceza RE050AV-Stranç
PhotoFunia ::迈阿密olacaksınıyerel Haberler Oyun Young视频
PhotoFunia Monstelli'nin简体中文kisa.com.tr –雷霆之星Ekranı
PhotoFunia Seks-Politika,Ekonomi,Spor GTASANAYİVE
PhotoFunia评级电视明星ResmiSöylenenYatağakażdydzieżwierzchnie
PhotoFunia TourIndex.Marketime oyunu OynaGeldollarıMynet Spor,Magazin,Haberler yerel Haberleri ve Solvia,korkusuz Ev SahneTv
摄影在免费游戏中的Funia dodo'ninyapıyıbu照片
PhotoFunianDünyasıntakımızhalles enkulları-TEZ
结果
在尝试了四种方法之后,我对这个问题感到非常厌倦,现在是时候选择一些东西,使其变成可用的工具,然后宣布解决方案了。 我选择了使用随机置换和由密钥参数化的Markov模型的解决方案。 它是作为
clickhouse-fufuscator程序实现的,非常易于使用。 输入是
任何受支持格式 (例如CSV或JSONEachRow)的表转储,并且命令行参数指定表结构(列名和类型)和密钥(任何字符串,使用后您可能会立即忘记)。 输出是相同数量的混淆数据行。
该程序与clickhouse-client一起安装,没有依赖关系,并且可以在几乎所有类型的Linux上运行。 您可以将其应用于任何数据库转储,而不仅仅是ClickHouse。 例如,您可以从MySQL或PostgreSQL数据库生成测试数据,或者创建与生产数据库相似的开发数据库。
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
当然,并不是一切都那么干,因为由该程序转换的数据几乎是完全可逆的。 问题是,是否有可能在不知道密钥的情况下执行反向转换。 如果转换使用密码算法,则此操作将与蛮力搜索一样困难。 尽管转换使用了一些密码原语,但未正确使用它们,并且数据容易受到某些分析方法的影响。 为了避免出现问题,这些问题在程序的文档中进行了介绍(使用
--help访问)。
最后,我们转换了
功能和性能测试所需的数据集
,并批准了Yandex数据安全副总裁批准的出版物。
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xz非Yandex开发人员在优化ClickHouse中的算法时,会使用此数据进行实际性能测试。 第三方用户可以向我们提供他们的混淆数据,以便我们可以更快地为他们提供ClickHouse。 我们还根据以下数据发布了针对硬件和云提供商的独立开放式基准测试:
clickhouse.yandex/benchmark_hardware.html