 这是最精彩的Unicode“好东西”以及软件包和资源的更新列表。
这是最精彩的Unicode“好东西”以及软件包和资源的更新列表。Unicode很棒! 在它出现之前,国际交流就已经精疲力尽:每个人都在ASCII的上半部分(即所谓的代码页)中定义了自己的扩展字符集。 这造成了冲突。 试想一下,德国人必须与韩国人进行谈判,其代码页在哪里。 幸运的是,Unicode出现并引入了一个通用标准。 Unicode 8.0包含来自129多个脚本的120,000个字符。 无论是现代的还是古代的,仍然没有被解密。 Unicode支持从左到右和从右到左的文本,覆盖字符,并包括各种文化,政治,宗教符号和表情符号。 Unicode非常人性化,其功能被大大低估了。
目录内容
简要介绍
Unicode标准中包含哪些字符?
Unicode标准定义了主要现代语言中字符的代码。 这些是欧洲字母脚本,从右到左的中东脚本以及许多亚洲脚本。
该标准还包含标点符号,变音符号,数学符号,技术符号,箭头,装饰符号,表情符号等。它为变音符号提供了更改字符符号的代码,例如波浪号(〜)。 它们与基本字符结合使用以表示重音字符(例如ñ)。 通常,Unicode版本9.0提供了来自世界字母表,表意文字集和字符集的128,172个字符的代码。
最常见的字符放置在前64K代码点中,这是代码空间的一个区域,称为主多语言平面,简称BMP。 还有其他十六种其他平面可用于编码其他字符,其中有超过850,000个未使用的代码点。 他们可能会派上用场,以便在将来的标准版本中添加新字符。
Unicode标准还保留了代码点供私人使用。 供应商或最终用户可以在自己的系统中为其字符指定字符,或将它们与专用字体一起使用。 如果6400不足以用于特定应用,则BMP具有6400个供私人使用的代码点和131068个供私人使用的其他代码点。
Unicode字符编码
字符编码标准不仅确定每个字符的标识及其数字值或代码点,还确定如何以位表示此值。
Unicode标准定义了三种编码形式,它们允许传输相同的数据:一个字节,一个字和一个双字(即,每单位代码8、16或32位)。 所有这三种形式都编码相同的公共字符集,并且可以有效地相互转换而不会丢失数据。 Unicode协会完全认可使用这些编码形式中的任何一种作为实现Unicode标准的公认方式。
UTF-8在HTML和类似协议中很流行。 UTF-8是将所有Unicode字符转换为可变字节长度编码的一种方式。 它的优点是,与熟悉的ASCII集相对应的Unicode字符具有与ASCII相同的字节值,并且转换为UTF-8的Unicode字符可以与许多现有软件一起使用,而无需进行重大软件修改。
UTF-16在许多需要平衡对字符的有效访问与经济存储之间的环境中很流行。 它非常紧凑,所有常用字符都放在一个16位代码块中,而其他所有字符都可以通过成对的16位代码块使用。
UTF-32在不考虑内存量但需要访问单个固定宽度代码中的字符的情况下很有用。 在这里,每个Unicode字符都被编码在单个32位代码块中。
所有三种编码形式的每个字符都要求不超过4个字节(或32位)。
谈论数字
Unicode字符集分为17个主要段(平面),这些主要段又分为块。 在每个平面中都有65 536(2
16 )个代码点的位置,总共创建了1,114,112个代码点。 公司/用户自行决定分配两个“专用平面”(第16号和第17号)以供使用。 它们具有131,072个代码点。
第一个平面称为主多语言平面或BMP。 它包含从U + 0000到U + FFFF的代码点,即最常用的字符。 其余的十六个平面(U + 010000→U + 10FFFF)被称为附加或星空。
代理对UTF-16
主平面外部的符号(如表示中心的四卦符号(U + 1D306))可以用仅两个16位代码单元的UTF-16编码:0xD834 0xDF06。 这称为代理对。 请注意,代理对仅代表一个字符。
代理对的第一个代码单元始终在0xD800到0xDBFF的范围内,被称为对的第一部分。
代理对的第二个代码单元始终在0xDC00到0xDFFF的范围内,被称为该对的底部。
马蒂亚斯·比恩斯(Matthias Binens)
代理对:一个抽象符号的表示形式,由两个16位代码单元的序列组成,其中该对的第一个值是顶部代理代码单元,第二个是较低代理代码单元。 代理对仅在UTF-16中使用。
Unicode 8.0第3.8章-替代
代理对的计算
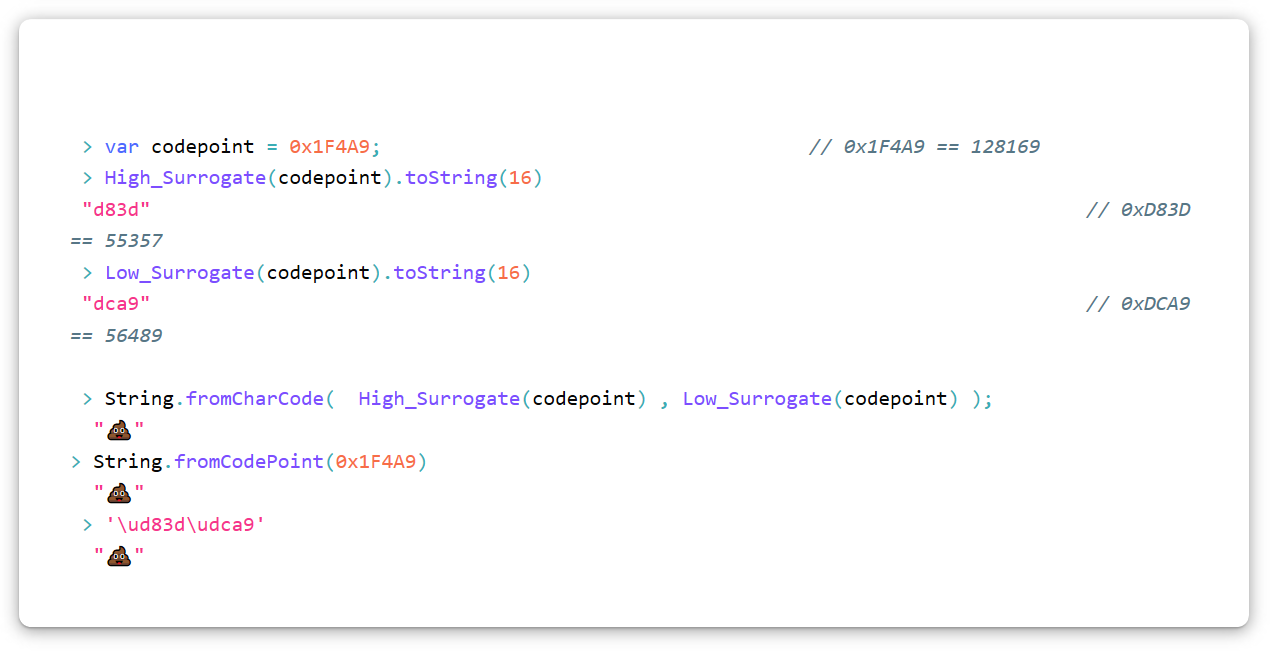
UTF-16中的Unicode字符“堆屎”(U + 1F4A9)必须编码为一个代理对,即两个代理。 要将任何代码点转换为代理对,请使用此算法(在JavaScript中)。 请记住,我们使用十六进制表示法。
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
组成与分解
Unicode包含一种更改字符形状的机制,该机制大大扩展了支持的字形集。 这适用于可组合变音符号。 它们被插入到主角之后。 多个变音标记可以应用于同一标记。 Unicode还包含大多数此类组合的预编译版本,以供正常使用。
某些字符序列也可以表示为单个字符,称为预组合字符,也称为复合字符。 例如,可以将字符[ü]编码为唯一的代码点U + 00FC或基本字符U + 0075(u),然后再编码为非独立字符U + 0308(¨)。 Unicode标准对复合字符进行编码,以与既定标准兼容,例如Latin 1,其中包括许多复合字符,例如[ü]和[ñ]。
可以扩展复合字符以进行一致性或分析。 例如,当按字母顺序排序时,符号[ü]可以分解为[u],后跟非独立符号[¨]。 经过这样的分解,该算法更易于处理一系列字符。 这使得在字符修饰符不影响字母顺序的语言中更容易进行排序。 Unicode标准设置所有复合字符的
分解顺序 。 它还定义了规范化形式以提供字符的唯一表示形式。
Unicode神话
摘自Mark Davis的幻灯片“ Unicode的神话” 。- Unicode只是16位代码 。 -有些人错误地认为Unicode只是一个16位代码,其中每个字符占用16位,因此有65,536个可能的字符。 实际上,这并非完全正确。 这是最常见的Unicode神话,因此如果您之前也这么认为,请不要气disc。
- 您可以采用未满足您需求的任何代码点 。 -不 总有一天,这个地方会被另一个符号代替。 取而代之的是,将飞机用于私人用途,或者在每个飞机上没有字符的区域中,根据标准,这些字符将不包含字符。
- 每个Unicode代码点代表一个字符 。 -不 有很多不带字符的点(FFFE,FFFF,1FFFE等),此外,还包括替代代码点,私有和未使用的代码点,以及控制/格式化“字符”(RLM,ZWNJ等)。
- Unicode空间不足 。 -如果线性填充,它将在2140年结束。 但是该位置不是线性填充的。 将来的计划请看这里 。
- 所有字符都一一对应 。 -不 选项包括:
- 一对多:(β→SS)
- 给定上下文:(...Σ←→...ς并同时...ΣΤ...←→...στ...)
- 根据语言环境:(I←→ı,同时İ←→i)
Unicode应用程序编码
源代码
令人惊叹的角色列表。
从U + 202a到U + 202e的管理人员的安排越来越混乱,共享文档可以迅速将编辑变成书面说唱战特殊字符
Unicode联盟已发布
了通用标点图 ,您可以在其中找到更多信息。
等等...我刚刚读了什么?变量标识符可以包含空格!
U + 3164 Hangul占位符显示为宽空格。 如果
在渲染中显然不
支持该字符,则该字符将显示为完全不可见(并且不占用空间,即“零宽度”)。 这意味着您将永远不会看到丑陋的字符替换字符( )。
我还不确定为什么要指示U + 3164以这种方式运行。 有趣的是,U + 3164在1.1版(1993年)中添加到Unicode中-因此,联盟专家有很多时间来考虑它。 无论如何,这里有一些例子。
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
**注:**我在Ubuntu和OS X上使用以下参数测试了U + 3164渲染:`node`,`php`,`ruby`,`python3.5`,`scala`,`vim`,`cat` ,`chrome` +`github gist'。 Atom是唯一失败(错误地)显示空白字段的系统。 我尚未检查Emacs和Sublime中的代码。 据我了解,Unicode联盟不会重新分配或重命名字符或代码点,但是可以说服它更改字符的属性,例如ID_Start和ID_Continue。修饰符
零宽度组合器(ZWJ)是计算机中某些复杂字体(例如阿拉伯语或任何印度字体)中的不可打印字符。 当ZWJ放置在否则无法连接的两个字符之间时,将强制它们以组合形式打印。
零宽度隔离器(ZWNJ)是带有连字的基于计算机的书写集中的不可打印字符。 当放置在两个本来要连字的字符之间时,ZWNJ会强制它们分别以最终形式和原始形式打印。 充当空格,但在需要使单词彼此靠近或将单词与其词素结合在一起时使用。
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
大写变换冲突
小写转换冲突
怪癖和故障排除
- 线长通常由代码点数决定 。 这意味着代理对将被视为两个字符。 几个变音符号可以叠加在一个符号上:
a + ̈ == ̈a 。 这增加了字符串的长度,仅产生一个字符。
- 同样,字符串倒置通常成为一项不平凡的任务 。 同样,代理对和变音符号应一起反转。 ES Reverser提供了一个很好的解决方案。
- 大写和小写比较并不总是匹配 。 它们可以用以下关系表示:
- 一对多:(ß→SS)
- 给定上下文:(...Σ←→...ς和...ΣΤ...←→...στ...)
- 基于语言环境:(I←→ı和İ←→i)
一对多比较
下面的大多数字符以大写形式表示它们的一对多映射,以小写形式表示其他字符。 原则上,列表可以分为两部分。
很棒的软件包和库
表情符号
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .