本文是我在“媒介
-Data Lake入门 ”上的文章的翻译,结果证明它很受欢迎,可能是因为它很简单。 因此,我决定用俄语编写它,并对它进行一些补充,以便不是数据专家的简单人可以理解什么是数据仓库(DW),什么是数据湖以及他们如何相处。 。
我为什么要写一个数据湖? 我从事数据和分析工作已超过10年,现在,我绝对在位于波士顿的剑桥市的Amazon Alexa AI上处理大数据,尽管我本人住在温哥华岛的维多利亚州,并且经常访问波士顿,西雅图和温哥华,有时甚至在莫斯科,我都在会议上发言。 另外,我不时写作,但我主要用英语写作,并且已经写
了几本书 ,而且我还需要分享北美的分析趋势,有时我会用
电报来写作。
我一直与数据仓库合作,自2015年以来,我开始与Amazon Web Services紧密合作,并且通常转而使用云分析(AWS,Azure,GCP)。 我观察了自2007年以来分析解决方案的发展,甚至在Teradat数据仓库供应商中工作,并在Sberbank中实施了该解决方案,然后出现了带有Hadoop的大数据。 每个人都开始说存储时代已经过去,现在一切都在Hadoop上,然后他们又开始谈论Data Lake,现在数据仓库肯定已经过去了。 但是幸运的是(也许对于不幸的是,某人在建立Hadoop上赚了很多钱),数据仓库并没有消失。
在本文中,我们将考虑什么是数据湖。 本文适用于很少或没有数据仓库经验的人。

在图片中,布莱德湖是我最喜欢的湖泊之一,虽然我只去过一次,但我终生难忘。 但是我们将讨论另一种类型的湖泊-数据湖。 也许你们中的许多人已经不止一次听说过这个词,但是另一个定义不会伤害任何人。
首先,以下是Data Lake的最流行定义:
“组织中任何人都可以进行分析的所有类型的原始数据的文件存储”-Martin Fowler。
“如果您认为数据展示柜是一瓶水-经过纯化,包装和包装以方便使用,那么数据湖就是其天然形式的巨大水库。 用户,我可以为自己取水,潜入深处,探索“-詹姆斯·迪克森。
现在我们可以确定数据湖与分析有关,它可以让我们以原始格式存储大量数据,并且可以对数据进行必要且方便的访问。
我经常喜欢简化事情,如果我能用简单的话说一个复杂的术语,那么对我自己来说,我就会理解它的工作原理和目的。 不知何故,我在照相馆里拿起我的iPhone,它突然出现在我身上,所以这是一个真正的数据湖,我什至为会议制作了一张幻灯片:

一切都非常简单。 我们在手机上拍照,照片被保存在手机上,并且可以保存在iCloud(云中的文件存储)中。 手机还收集照片的元数据:显示的内容,地理标记,时间。 结果,我们可以使用便捷的iPhone界面查找照片,同时甚至可以看到指示符,例如,当我查找带有火字的照片时,我会发现3张带有火影的照片。 对我来说,它就像一个可以快速,清晰地运行的商业智能工具。
当然,我们不应该忘记安全性(授权和身份验证),否则我们的数据很容易进入公开访问。 关于大型公司和初创企业的新闻很多,由于开发商的疏忽和不遵守简单规则,数据进入了公共领域。
即使如此简单的图片也可以帮助我们想象什么是数据湖,它与传统数据仓库的区别及其主要元素:
- 数据加载 (提取)是数据湖的关键组成部分。 数据可以通过两种方式进入数据仓库-批处理(间隔下载)和流式传输(数据流)。
- 文件存储是数据湖的主要组成部分。 我们需要存储易于扩展,极其可靠且成本低廉。 例如,在AWS中,这是S3。
- 目录和搜索 -为了避免数据沼泽(这是我们将所有数据转储为一堆,然后就无法使用它们的情况),我们需要创建一个元数据层来对数据进行分类,以便用户可以轻松地找到他们需要分析的数据。 此外,您可以使用其他搜索解决方案,例如ElasticSearch。 搜索可帮助用户通过方便的界面搜索所需的数据。
- 处理 (Process)-此步骤负责数据的处理和转换。 我们可以转换数据,更改其结构,清除数据等等。
- 安全性 -花时间设计安全性解决方案很重要。 例如,在存储,处理和加载期间的数据加密。 使用身份验证和授权方法很重要。 总之,需要一个审计工具。
从实际的角度来看,我们可以表征具有三个属性的数据湖:
- 收集并存储您想要的任何内容 -数据湖包含所有数据,包括任何时间段的原始数据和已处理/已清除的数据。
- 深度分析 -数据湖可让用户浏览和分析数据。
- 灵活的访问 -数据湖为各种数据和各种方案提供灵活的访问。
现在我们可以讨论数据仓库和数据湖之间的区别。 人们通常会问:
- 但是数据仓库呢?
- 我们是用数据湖代替数据仓库还是在扩展它?
- 没有数据湖是否有可能做?
简而言之,没有明确的答案。 这完全取决于具体情况,团队技能和预算。 例如,将数据仓库迁移到AWS中的Oracle并由亚马逊子公司Woot创建数据湖-
我们的数据湖故事:Woot.com如何在AWS上构建无服务器数据湖 。
另一方面,Snowflake供应商指出,您不再需要考虑数据湖,因为他们的数据平台(直到2020年以前都是数据仓库)允许您将数据湖和数据仓库结合在一起。 我与Snowflake的合作不多,这是一款可以做到这一点的真正独特的产品。 问题的价格是另一个问题。
总之,我个人的观点是,我们仍然需要数据仓库作为报告的主要数据源,并且我们存储所有不适合数据湖的内容。 分析的全部作用是为决策提供方便的业务访问。 无论如何,与Amazon的数据湖相比,业务用户使用数据仓库的效率更高。例如,在Amazon-有Redshift(分析数据仓库)和Redshift Spectrum / Athena(基于Hive / Presto的S3中用于数据湖的SQL接口)。 其他现代分析数据仓库也是如此。
让我们看一下典型的数据仓库架构:
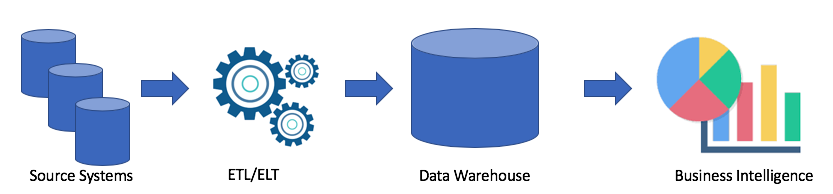
这是一个经典的解决方案。 我们有源系统,使用ETL / ELT,我们将数据复制到分析数据仓库中,并将解决方案连接到商业智能(我最喜欢的Tableau,还有您的Tableau?)。
该解决方案具有以下缺点:
- ETL / ELT操作需要时间和资源。
- 通常,在分析数据仓库中存储数据的内存并不便宜(例如Redshift,BigQuery,Teradata),因为我们需要购买整个集群。
- 业务用户可以访问已清理且通常是聚合的数据,并且无法获取原始数据。
当然,这完全取决于您的情况。 如果您的数据仓库没有问题,那么您绝对不需要数据湖。 但是,如果由于空间不足,容量不足或问题的价格而产生问题时,则可以考虑选择数据湖。 这就是为什么数据湖非常受欢迎。 这是数据湖架构的示例:

使用数据湖方法,我们将原始数据加载到数据湖中(批处理或流传输),然后根据需要处理数据。 数据湖使业务用户可以创建自己的数据转换(ETL / ELT)或在Business Intelligence解决方案中分析数据(如果您有合适的驱动程序)。
任何分析解决方案的目标都是为业务用户提供服务。 因此,我们必须始终根据业务需求进行工作。 (在亚马逊,这是原则之一-向后工作)。
通过使用数据仓库和数据湖,我们可以比较两种解决方案:
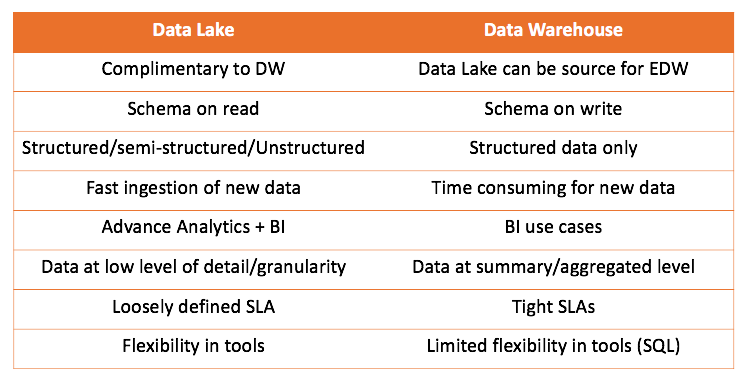
可以得出的主要结论是,数据仓库不会与数据湖竞争,而是会对其进行补充。 但这取决于您的情况。 自己尝试并得出正确的结论总是很有趣。
我还想谈一谈开始使用数据湖方法的情况之一。 一切都很普通,我尝试使用ELT工具(我们拥有Matillion ETL)和Amazon Redshift,虽然我的解决方案有效,但不符合要求。
我需要获取Web日志,对其进行转换并汇总以提供2种情况的数据:
- 营销团队希望分析针对SEO的机器人活动
- IT希望关注站点指标
非常简单,非常简单的日志。 这是一个例子:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
一个文件重1-4兆字节。
但是有一个困难。 我们在全球拥有7个域,一天之内创建了7,000万个文件。 这不是一个很大的卷,只有50 GB。 但是我们的Redshift集群的规模也很小(4个节点)。 以传统方式下载单个文件大约需要一分钟。 即,该任务没有在额头上解决。 当我决定使用数据湖方法时就是这种情况。 解决方案如下所示:
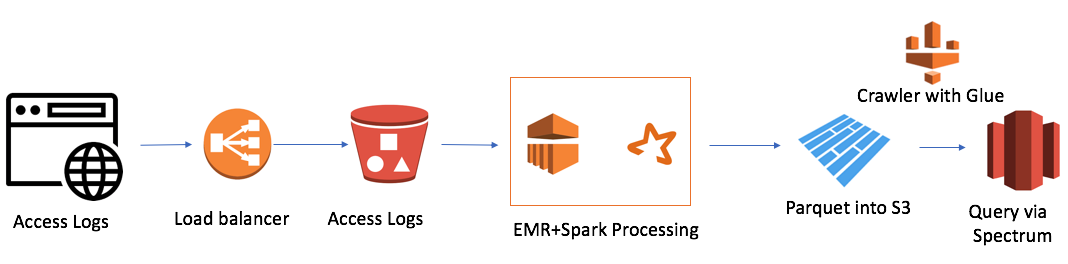
这非常简单(我想指出的是,在云中工作的优点是简单)。 我用过:
- AWS Elastic Map Reduce(Hadoop)作为计算能力
- AWS S3作为文件存储,具有加密数据和限制访问的能力
- Spark作为InMemory计算能力和PySpark用于逻辑和数据转换
- 由于Spark的实木复合地板
- AWS Glue Crawler作为有关新数据和分区的元数据的收集器
- Redshift Spectrum作为现有Redshift用户到数据湖的SQL接口
最小的EMR + Spark集群在30分钟内处理了一大堆文件。 AWS还有其他情况,尤其是与Alexa有关的许多情况,其中有大量数据。
最近,我发现数据湖的缺点之一是GDPR。 问题是当客户要求他删除数据并且数据在其中一个文件中时,我们不能像在数据库中那样使用数据操作语言和DELETE操作。
希望本文阐明了数据仓库和数据湖之间的区别。 如果很有趣,我仍然可以翻译我的文章或我读过的专业文章。 并且还讨论我使用的解决方案及其体系结构。